字符串截取
1 | str = ‘0123456789’ |
输出结果:
1 | 012 |
1 | str = ‘0123456789’ |
输出结果:
1 | 012 |
title: gradle使用 date: 2019-01-10 18:38:26 tags: [工具] categories: 工具
https://docs.gradle.org/current/userguide/customizing_dependency_resolution_behavior.html#sec:component_selection_rules http://google.github.io/android-gradle-dsl/current/ https://www.kotlincn.net/docs/reference/server-overview.html
https://blog.csdn.net/u010014658/article/details/78999031
gradle命令:
1 | 在build.gradle中添加如下配置: |
1 | project.getGradle().addListener(new DependencyResolutionListener() { |
1 | //1. 从命令行中解析出buildType |
1 | applicationVariants.all { variant -> |
1 | compile project(':libim',{ pj -> |
库中
1 | roject.getGradle().addListener(new DependencyResolutionListener() { |
之前一直用windows版的eclipse快捷键,现在准备切成mac原生快捷键映射.
特殊符号 :
Command + F 查找 Command + Option + F 替换 Command + G 查找下一个 Command + Shift + G 查找上一个 Option + Enter 选中所有匹配项 Command + D 向下选中相同内容 Command + K Command + D 移除前一个向下选中相同内容
Ctrl + Space 打开建议 Command + Shift + Space 参数提示 Tab Emmet插件缩写补全 Option + Shift + F 格式化 Command + K Command + F 格式化选中内容 F12 跳转到声明位置 Option + F12 查看具体声明内容 Command + K F12 分屏查看具体声明内容 Command + . 快速修复 Shift + F12 显示引用 F2 重命名符号 Command + Shift + . 替换为上一个值 Command + Shift + , 替换为下一个值 Command + K Command + X 删除行尾多余空格 Command + K M 更改文件语言
Command + T 显示所有符号 Ctrl + G 跳转至某行 Command + P 跳转到某个文件 Command + Shift + O 跳转到某个符号 Command + Shift + M 打开问题面板 F8 下一个错误或警告位置 Shift + F8 上一个错误或警告位置 Ctrl + Shift + Tab 编辑器历史记录 Ctrl + - 后退 Ctrl + Shift + - 前进 Ctrl + Shift + M Tab 切换焦点
Command + W 关闭编辑器 Command + K F 关闭文件夹 Command + \ 编辑器分屏 Command + 1 切换到第一分组 Command + 2 切换到第二分组 Command + 3 切换到第三分组 Command + K Command + Left 切换到上一分组 Command + K Command + Right 切换到下一分组 Command + K Command + Shift + Left 左移编辑器 Command + K Command + Shift + Right 右移编辑器 Command + K Left 激活左侧编辑组 Command + K Right 激活右侧编辑组
Command + N 新建文件 Command + O 打开文件 Command + S 保存文件 Command + Shift + S 另存为 Command + Option + S 全部保存 Command + W 关闭 Command + K Command + W 全部关闭 Command + Shift + T 重新打开被关闭的编辑器 Command + K Enter 保持打开 Ctrl + Tab 打开下一个 Ctrl + Shift + Tab 打开上一个 Command + K P 复制当前文件路径 Command + K R 在资源管理器中查看当前文件 Command + K O 新窗口打开当前文件
Command + Ctrl + F 全屏、退出全屏 Command + Option + 1 切换编辑器分屏方式(横、竖) Command + + 放大 Command + - 缩小 Command + B 显示、隐藏侧边栏 Command + Shift + E 显示资源管理器 或 切换焦点 Command + Shift + F 显示搜索框 Ctrl + Shift + G 显示Git面板 Command + Shift + D 显示调试面板 Command + Shift + X 显示插件面板 Command + Shift + H 全局搜索替换 Command + Shift + J 显示、隐藏高级搜索 Command + Shift + C 打开新终端 Command + Shift + U 显示输出面板 Command + Shift + V Markdown预览窗口 Command + K V 分屏显示 Markdown预览窗口
F9 设置 或 取消断点 F5 开始 或 继续 F11 进入 Shift + F11 跳出 F10 跳过 Command + K Command + I 显示悬停信息
Ctrl + 显示终端
Ctrl + Shift + 新建终端
Command + Up 向上滚动
Command + Down 向下滚动
PgUp 向上翻页
PgDown 向下翻页
Command + Home 滚动到顶部
Command + End 滚动到底部
pip install yapf安装yapf,安装yapf成功后,打开VScode,文件->首选项->用户设置,在settings.json文件中输入”python.formatting.provider”: “yapf”
Alt+Shift+F即可格式化代码
格式化json: mac下 cmd + alt +M
url encode URIDecode cmd+U+D URIEncode cmd+U+E
上传图片到七牛云: ctrl+alt+O
从Android6.0版本开始google将权限分为普通权限和特殊权限,app必须在AndroidManifest.xml添加引用权限的语句。 在安装apk时安卓会将普通权限授予该app,但特殊权限需要运行时申请。
安卓按照权限类别分为权限组和权限, 每个权限都隶属于一个权限组。 当安卓系统授权一个权限时, 那么该权限所属权限组的权限都会自动被授权。
目前如果app的targetSdkVersion等于21,即按照Android5.0版本特性运行。 技术层面与市场上主流app差距较大, 功能层面也有一些功能可能失效(例如在一些机型上无法打电话、读写SD卡), 根本原因是没适配动态权限。
判断当前手机系统是Android6.0及以上版本, 在Activity/Fragment里申请权限并处理权限结果回调。 这里要说明一下:Fragment是通过Activity申请权限的, 且权限回调onRequestPermissionResult也是Activity调用的Fragment该方法.
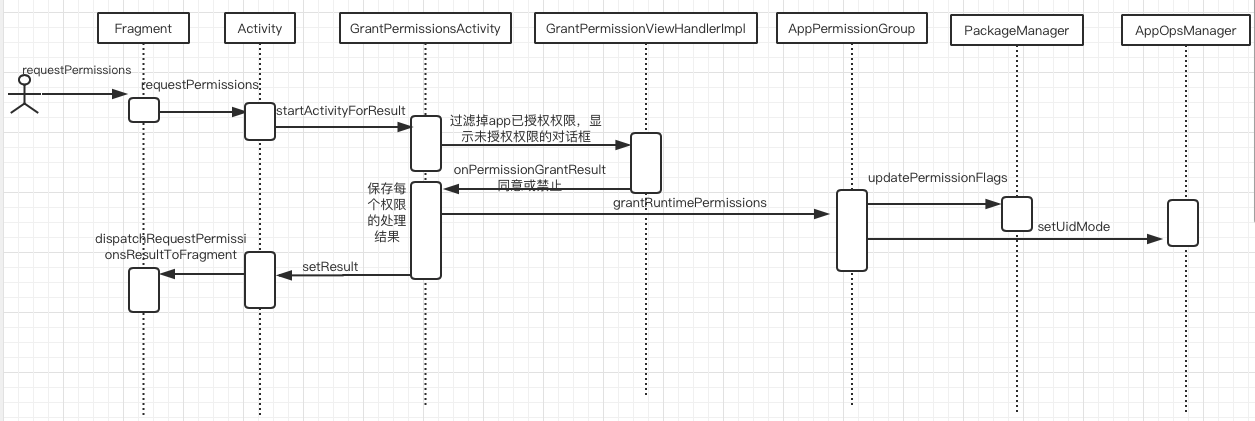 上图是权限申请流程图, 我们看到的权限弹窗对应/packages/apps/PackageInstaller/src/com/android/packageinstaller/permission/ui/GrantPermisssionsActivity.java, 点击“同意”或“不同意”通过PackageManager、AppOpsManager将权限操作更新到PackageManagerService和AppOpsService中。
上图是权限申请流程图, 我们看到的权限弹窗对应/packages/apps/PackageInstaller/src/com/android/packageinstaller/permission/ui/GrantPermisssionsActivity.java, 点击“同意”或“不同意”通过PackageManager、AppOpsManager将权限操作更新到PackageManagerService和AppOpsService中。
调用Activity的申请权限方法其实是打开一个系统的Activity,操作结果通过setResult返回过来。
能不能直接调用PackageManager/AppOpsManagerd的方法授权给自己? 显然是不行的, PackageManagerService只允许在AndroidManifest.xml配置coreApp=”true”的应用修改权限,而普通app无法设置coreApp属性。
1 | public int getPermissionFlags(String name, String packageName, int userId) { |
 如上图所示,判断是否有权限最终会执行到PackagerManagerService的checkUidPermission函数中。
如上图所示,判断是否有权限最终会执行到PackagerManagerService的checkUidPermission函数中。
示例代码: 为了避免适配动态权限逻辑产生风险, 可以新增if代码块做动态权限逻辑, else分支仍然是现有逻辑。 各业务线可能无法在同一个版本上搞定, 可以按照这种写法先后完成动态权限适配工作,待所有业务线都完成后调整宿主targetSdkVersion到26。
1 | if (getBaseContext().getApplicationInfo().targetSdkVersion >= Build.VERSION_CODES.M |
1 | /** |
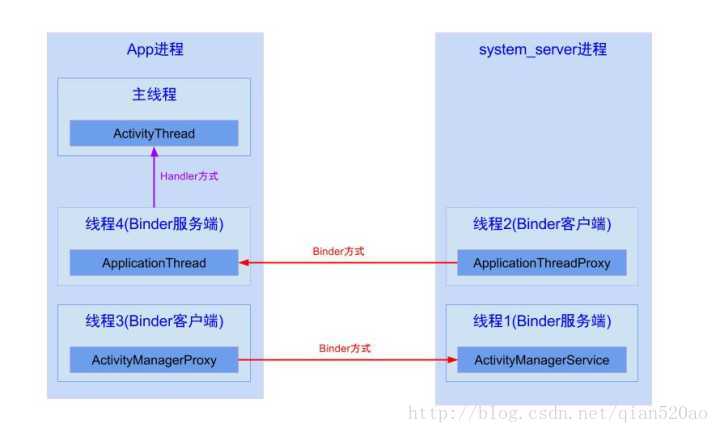
system_server进程是系统进程,java framework框架的核心载体,里面运行了大量的系统服务,比如这里提供ApplicationThreadProxy(简称ATP),ActivityManagerService(简称AMS),这个两个服务都运行在system_server进程的不同线程中,由于ATP和AMS都是基于IBinder接口,都是binder线程,binder线程的创建与销毁都是由binder驱动来决定的。
App进程则是我们常说的应用程序,主线程主要负责Activity/Service等组件的生命周期以及UI相关操作都运行在这个线程; 另外,每个App进程中至少会有两个binder线程 ApplicationThread(简称AT)和ActivityManagerProxy(简称AMP),除了图中画的线程,其中还有很多线程
Binder用于不同进程之间通信,由一个进程的Binder客户端向另一个进程的服务端发送事务,比如图中线程2向线程4发送事务;而handler用于同一个进程中不同线程的通信,比如图中线程4向主线程发送消息。
结合图说说Activity生命周期,比如暂停Activity,流程如下:
ActivityThread通过ApplicationThread和AMS进行进程间通讯,AMS以进程间通信的方式完成ActivityThread的请求后会回调ApplicationThread中的Binder方法,然后ApplicationThread会向H发送消息,H收到消息后会将ApplicationThread中的逻辑切换到ActivityThread中去执行,即切换到主线程中去执行,这个过程就是主线程的消息循环模型
进程 每个app运行时前首先创建一个进程,该进程是由Zygote fork出来的,用于承载App上运行的各种Activity/Service等组件。进程对于上层应用来说是完全透明的,这也是google有意为之,让App程序都是运行在Android Runtime。大多数情况一个App就运行在一个进程中,除非在AndroidManifest.xml中配置Android:process属性,或通过native代码fork进程。
线程 线程对应用来说非常常见,比如每次new Thread().start都会创建一个新的线程。该线程与App所在进程之间资源共享,从Linux角度来说进程与线程除了是否共享资源外,并没有本质的区别,都是一个task_struct结构体,在CPU看来进程或线程无非就是一段可执行的代码,CPU采用CFS调度算法,保证每个task都尽可能公平的享有CPU时间片。
其实承载ActivityThread的主线程就是由Zygote fork而创建的进程。
Handler创建的时候会采用当前线程的Looper来构造消息循环系统,Looper在哪个线程创建,就跟哪个线程绑定,并且Handler是在他关联的Looper对应的线程中处理消息的。(敲黑板)
那么Handler内部如何获取到当前线程的Looper呢—–ThreadLocal。ThreadLocal可以在不同的线程中互不干扰的存储并提供数据,通过ThreadLocal可以轻松获取每个线程的Looper。当然需要注意的是①线程是默认没有Looper的,如果需要使用Handler,就必须为线程创建Looper。我们经常提到的主线程,也叫UI线程,它就是ActivityThread,②ActivityThread被创建时就会初始化Looper,这也是在主线程中默认可以使用Handler的原因。
系统为什么不允许在子线程中访问UI? 这是因为Android的UI控件不是线程安全的,如果在多线程中并发访问可能会导致UI控件处于不可预期的状态,那么为什么系统不对UI控件的访问加上锁机制呢?缺点有两个:
Android应用程序是通过消息来驱动的,Android某种意义上也可以说成是一个以消息驱动的系统,UI、事件、生命周期都和消息处理机制息息相关,并且消息处理机制在整个Android知识体系中也是尤其重要,在太多的源码分析的文章讲得比较繁琐,很多人对整个消息处理机制依然是懵懵懂懂,这篇文章通过一些问答的模式结合Android主线程(UI线程)的工作原理来讲解,源码注释很全,还有结合流程图
消息处理机制本质:一个线程开启循环模式持续监听并依次处理其他线程给它发的消息。
简单的说:一个线程开启一个无限循环模式,不断遍历自己的消息列表,如果有消息就挨个拿出来做处理,如果列表没消息,自己就堵塞(相当于wait,让出cpu资源给其他线程),其他线程如果想让该线程做什么事,就往该线程的消息队列插入消息,该线程会不断从队列里拿出消息做处理。
打个比方:公司类比App
这里先给一张Android消息处理机制流程图和具体执行动画,如果看不懂没事,接着往下看(后面会结合Android UI主线程来讲解),然后结合着图和动画一块看更能理解整个机制的实现原理。
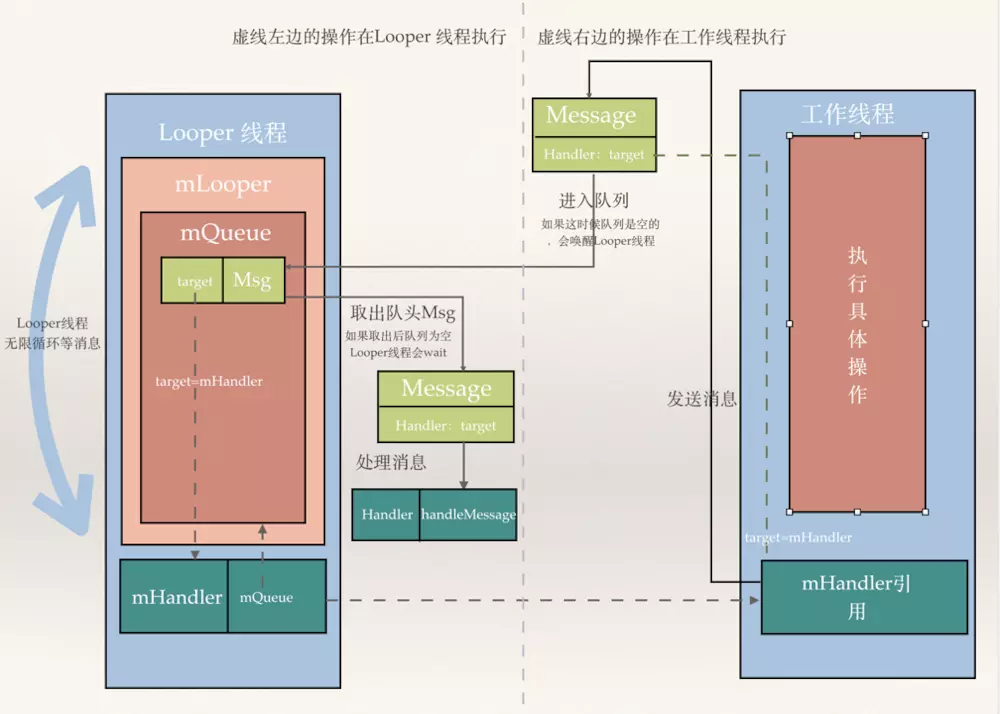
Looper 我们知道一个线程是一段可执行的代码,当可执行代码执行完成后,线程生命周期便会终止,线程就会退出,那么做为App的主线程,如果代码段执行完了会怎样?,那么就会出现App启动后执行一段代码后就自动退出了,这是很不合理的。所以为了防止代码段被执行完,只能在代码中插入一个死循环,那么代码就不会被执行完,然后自动退出,怎么在在代码中插入一个死循环呢?那么Looper出现了,在主线程中调用Looper.prepare()…Looper.loop()就会变当前线程变成Looper线程(可以先简单理解:无限循环不退出的线程),Looper.loop()方法里面有一段死循环的代码,所以主线程会进入while(true){…}的代码段跳不出来,但是主线程也不能什么都不做吧?其实所有做的事情都在while(true){…}里面做了,主线程会在死循环中不断等其他线程给它发消息(消息包括:Activity启动,生命周期,更新UI,控件事件等),一有消息就根据消息做相应的处理,Looper的另外一部分工作就是在循环代码中会不断从消息队列挨个拿出消息给主线程处理。
MessageQueue MessageQueue 存在的原因很简单,就是同一线程在同一时间只能处理一个消息,同一线程代码执行是不具有并发性,所以需要队列来保存消息和安排每个消息的处理顺序。多个其他线程往UI线程发送消息,UI线程必须把这些消息保持到一个列表(它同一时间不能处理那么多任务),然后挨个拿出来处理,这种设计很简单,我们平时写代码其实也经常这么做。每一个Looper线程都会维护这样一个队列,而且仅此一个,这个队列的消息只能由该线程处理。
Handler 简单说Handler用于同一个进程的线程间通信。Looper让主线程无限循环地从自己的MessageQueue拿出消息处理,既然这样我们就知道处理消息肯定是在主线程中处理的,那么怎样在其他的线程往主线程的队列里放入消息呢?其实很简单,我们知道在同一进程中线程和线程之间资源是共享的,也就是对于任何变量在任何线程都是可以访问和修改的,只要考虑并发性做好同步就行了,那么只要拿到MessageQueue 的实例,就可以往主线程的MessageQueue放入消息,主线程在轮询的时候就会在主线程处理这个消息。那么怎么拿到主线程 MessageQueue的实例,是可以拿到的(在主线程下mLooper = Looper.myLooper();mQueue = mLooper.mQueue;),但是Google 为了统一添加消息和消息的回调处理,又专门构建了Handler类,你只要在主线程构建Handler类,那么这个Handler实例就获取主线程MessageQueue实例的引用(获取方式mLooper = Looper.myLooper();mQueue = mLooper.mQueue;),Handler 在sendMessage的时候就通过这个引用往消息队列里插入新消息。Handler 的另外一个作用,就是能统一处理消息的回调。这样一个Handler发出消息又确保消息处理也是自己来做,这样的设计非常的赞。具体做法就是在队列里面的Message持有Handler的引用(哪个handler 把它放到队列里,message就持有了这个handler的引用),然后等到主线程轮询到这个message的时候,就来回调我们经常重写的Handler的handleMessage(Message msg)方法。
Message Message 很简单了,你想让主线程做什么事,总要告诉它吧,总要传递点数据给它吧,Message就是这个载体。
接下来我们会结合App主线程(UI线程)来讲解,从App启动后一步一步往下走分析整个Android的消息处理机制,首先在ActivityThread类有我们熟悉的main的函数,App启动的代码的入口就在这里,UI线程本来只是一个普通线程,在这里会把UI线程转换成Looper线程,什么是Looper线程,不急往下看就知道了。
1 | public final class ActivityThread { |
首先执行的是 Looper.prepareMainLooper() 我们来看下Looper里面的这个方法做了什么?
注:看之前先稍微了解下ThreadLocal是什么? ThreadLocal: 线程本地存储区(Thread Local Storage,简称为TLS),每个线程都有自己的私有的本地存储区域,不同线程之间彼此不能访问对方的TLS区域。这里线程自己的本地存储区域存放是线程自己的Looper。具体看下ThreadLocal.java 的源码!
1 | public final class Looper { |
看了上面的代码(仔细看下注释),我们发现 Looper.prepareMainLooper()做的事件就是new了一个Looper实例并放入Looper类下面一个static的ThreadLocal
接下来重点是看下Looper的构造函数,看看在new Looper的时候做了什么事?
1 | private Looper(boolean quitAllowed) { |
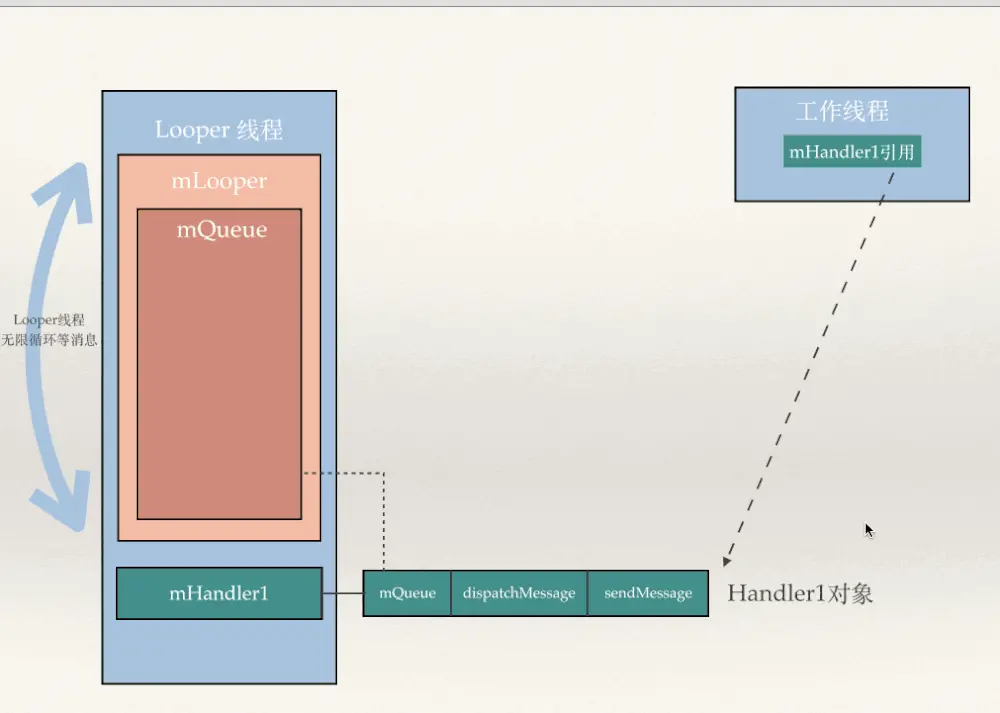
看到没有,这时候给当前线程创建了消息队列MessageQueue,并且让Looper持有MessageQueue的引用。执行完Looper.prepareMainLooper() 之后,主线程从普通线程转成一个Looper线程。目前的主线程线程已经有一个Looper对象和一个消息队列mQueue,引用关系如下图:(主线程可以轻松获取它的Looper,主线程的Looper持有主线程消息队列的引用)
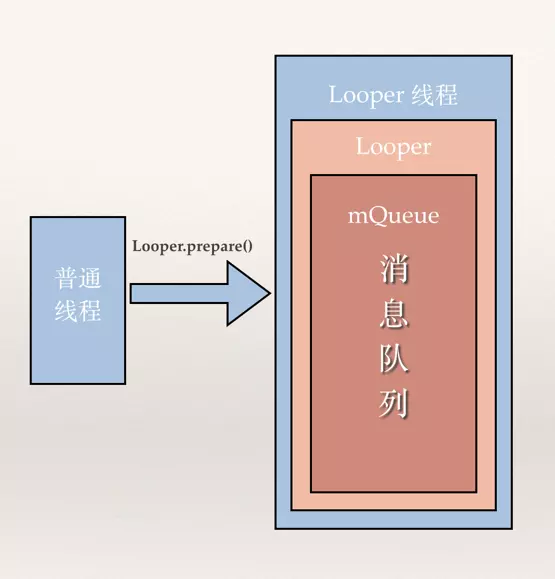 具体如何获取主线程的Looper对象和消息列表呢?
具体如何获取主线程的Looper对象和消息列表呢?
1 | //在主线程中执行 |
接下来回到ActivityThread 的main函数,执行完Looper.prepareMainLooper() 之后下一句代码是ActivityThread thread = new ActivityThread();这句话就是创建一下ActivityThread对象,这边需要注意的时候ActivityThread并不是一个线程,它并没有继承Thread,而只是一个普通的类public final class ActivityThread{…}ActivityThread的构造函数并没有做什么事只是初始化了资源管理器。
1 | ActivityThread() { |
接着往下看下一行代码
1 | ActivityThread thread = new ActivityThread(); |
thread.attach(false);便会创建一个Binder线程(具体是指ApplicationThread,该Binder线程会通过想 Handler将Message发送给主线程,之后讲)。我们之前提到主线程最后会进入无限循环当中,如果没有在进入死循环之前创建其他线程,那么待会谁会给主线程发消息呢?,没错就是在这里创建了这个线程,这个线程会接收来自系统服务发送来的一些事件封装了Message并发送给主线程,主线程在无限循环中从队列里拿到这些消息并处理这些消息。(Binder线程发生的消息包括LAUNCH_ACTIVITY,PAUSE_ACTIVITY 等等)
继续回到mian 函数的下一句代码Looper.loop() 那么重点来了,我们来看下Looper.loop()的源码:
1 | public static void loop() { |
上面的代码,大家具体看下注释,这时候主线程(UI线程)执行到这一步就进入了死循环,不断地去拿消息队列里面的消息出来处理?那么问题来了
1 | Message next() |
nativePollOnce()很重要,是一个native的函数,在native做了大量的工作,主要涉及到epoll机制的处理(在没有消息处理时阻塞在管道的读端),具体关于native相关的源码本篇文章不涉及,感兴趣的同学可以网上找找,有不少分析得比较深。
分析到这里,从应用启动创建Looper,创建消息队列,到进入loop方法执行无限循环中,那么这一块就告一段落了,主线程已经在死循环里轮询等待消息了,接下来我们就要再看看,系统是怎么发消息给主线程的,主线程是怎么处理这些个消息的?
在准备启动一个Activity的时候,系统服务进程下的ActivityManagerService(简称AMS)线程会通过Binder发送IPC调用给APP进程,App进程接到到调用后,通过App进程下的Binder线程最终调用ActivityThread类下面的scheduleLaunchActivity方法来准备启动Activity,看下scheduleLaunchActivity方法:
注:Binder线程:具体是指ApplicationThread,在App进程中接受系统进程传递过来的信息的线程(在主线程进入死循环之前创建了这个线程)。
1 | //这个方法不是在主线程调用,是Binder线程下调用的 |
把启动一些信息封装成ActivityClientRecord之后,最后一句调用sendMessage(H.LAUNCH_ACTIVITY, r);我们接着往下看:
1 | private void sendMessage(int what, Object obj) { |
看到没有,最后启动Activity的信息都封装一个Message,但是这里有个问题了,之前在分析main函数的时候,完全没给出往主线程消息队列插入消息的方式,这里有了消息,但是怎么发到主线程的消息队列呢?最后一句又是重点mH.sendMessage(msg); mH 是什么呢?难道是Handler,我们来看下它是什么东西? 我们看了下ActivityThread 的成员变量,发现一句初始化的代码
1 | final H mH = new H(); |
继续往下看H是什么?
1 | public final class ActivityThread{ |
H 果不出其然是Handler,而且是ActivityThread的内部类,看了一下它的handleMessage 方法,LAUNCH_ACTIVITY、PAUSE_ACTIVITY、RESUME_ACTIVITY…好多好多,H 类帮我们处理了好多声明周期的事情。那么再回到mH.sendMessage(msg)这句代码上,在Binder线程执行mH.sendMessage(msg);,由主线程创建的Handler mH实例发送消息到主线程的消息队列里,消息队列从无到有,主线程堵塞被唤醒,主线程loop拿到消息,并回调mH的handleMessage 方法处理LAUNCH_ACTIVITY 等消息。从而实现Activity的启动。
讲到这里,基本一个启动流程分析完了,大家可能比较想知道的是 mH.sendMessage(msg); 关于Hanlder是怎么把消息发到主线程的消息队列的?我们接下来就讲解下Handler,首先看下Handler的源码!我们先来看看我们经常用的Handler的无参构造函数,实际调用的是Handler(Callback callback, boolean async)构造函数(看注释)
1 | public Handler() { |
上面的代码说明了下面几个问题:
1 | class LooperThread extends Thread { |
那么接下来,我们接着往下看Handler的sendMessage(msg)方法,这个方法也是比较重要的,也比较常用,Handler 有很多sendXXXX开头的方法sendMessageAtTime、sendEmptyMessageDelayed、sendEmptyMessage等等,都是用来给消息队列添加消息的,那么这些方法最终都会调用enqueueMessage来实现消息进入队列:
1 | private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) { |
我们再来看下MessageQueue 的enqueueMessage(msg, uptimeMillis)方法:
1 | boolean enqueueMessage(Message msg, long when) { |
最后我们再看下Handler 的dispatchMessage方法,这个方法在Looper线程从消息队列拿出来的时候,通过msg.target.dispatchMessage(msg)调用的。
1 | /** |
相关源码:
1 | framework/base/core/java/andorid/os/MessageQueue.java |
HandlerThread HandlerThread继承Thread,它是一种可以使用Handler的Thread,它的实现也很简单,在run方法中也是通过Looper.prepare()来创建消息队列,并通过Looper.loop()来开启消息循环(与我们手动创建方法基本一致),这样在实际的使用中就允许在HandlerThread中创建Handler了。
HandlerThread的本质也是线程,所以切记关联的Handler中处理消息的handleMessage为子线程。
IdleHandler
1 | /** |
根据注释可以了解到,这个接口方法是在消息队列全部处理完成后或者是在阻塞的过程中等待更多的消息的时候调用的,返回值false表示只回调一次,true表示可以接收多次回调。
1 | Looper.myQueue().addIdleHandler(new MessageQueue.IdleHandler() { |
ThreadLocal,很多地方叫做线程本地变量,也有些地方叫做线程本地存储,其实意思差不多。可能很多朋友都知道ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。 这句话从字面上看起来很容易理解,但是真正理解并不是那么容易。 我们还是先来看一个例子:
1 | class ConnectionManager { |
假设有这样一个数据库链接管理类,这段代码在单线程中使用是没有任何问题的,但是如果在多线程中使用呢?很显然,在多线程中使用会存在线程安全问题:第一,这里面的2个方法都没有进行同步,很可能在openConnection方法中会多次创建connect;第二,由于connect是共享变量,那么必然在调用connect的地方需要使用到同步来保障线程安全,因为很可能一个线程在使用connect进行数据库操作,而另外一个线程调用closeConnection关闭链接。
所以出于线程安全的考虑,必须将这段代码的两个方法进行同步处理,并且在调用connect的地方需要进行同步处理。这样将会大大影响程序执行效率,因为一个线程在使用connect进行数据库操作的时候,其他线程只有等待。
那么大家来仔细分析一下这个问题,这地方到底需不需要将connect变量进行共享?事实上,是不需要的。假如每个线程中都有一个connect变量,各个线程之间对connect变量的访问实际上是没有依赖关系的,即一个线程不需要关心其他线程是否对这个connect进行了修改的。
到这里,可能会有朋友想到,既然不需要在线程之间共享这个变量,可以直接这样处理,在每个需要使用数据库连接的方法中具体使用时才创建数据库链接,然后在方法调用完毕再释放这个连接。比如下面这样:
1 | class ConnectionManager { |
这样处理确实也没有任何问题,由于每次都是在方法内部创建的连接,那么线程之间自然不存在线程安全问题。但是这样会有一个致命的影响:导致服务器压力非常大,并且严重影响程序执行性能。由于在方法中需要频繁地开启和关闭数据库连接,这样不尽严重影响程序执行效率,还可能导致服务器压力巨大。
那么这种情况下使用ThreadLocal是再适合不过的了,因为ThreadLocal在每个线程中对该变量会创建一个副本,即每个线程内部都会有一个该变量,且在线程内部任何地方都可以使用,线程之间互不影响,这样一来就不存在线程安全问题,也不会严重影响程序执行性能。
但是要注意,虽然ThreadLocal能够解决上面说的问题,但是由于在每个线程中都创建了副本,所以要考虑它对资源的消耗,比如内存的占用会比不使用ThreadLocal要大。
在上面谈到了对ThreadLocal的一些理解,那我们下面来看一下具体ThreadLocal是如何实现的。
先了解一下ThreadLocal类提供的几个方法:
1 | public T get() { } |
get()方法是用来获取ThreadLocal在当前线程中保存的变量副本,set()用来设置当前线程中变量的副本,remove()用来移除当前线程中变量的副本,initialValue()是一个protected方法,一般是用来在使用时进行重写的,它是一个延迟加载方法,下面会详细说明。
首先我们来看一下ThreadLocal类是如何为每个线程创建一个变量的副本的。 先看下get方法的实现:
1 | /** |
第一句是取得当前线程,然后通过getMap(t)方法获取到一个map,map的类型为ThreadLocalMap。然后接着下面获取到<key,value>键值对,注意这里获取键值对传进去的是 this,而不是当前线程t。如果获取成功,则返回value值。如果map为空,则调用setInitialValue方法返回value。
我们上面的每一句来仔细分析:
首先看一下getMap方法中做了什么:
1 | /** |
可能大家没有想到的是,在getMap中,是调用当期线程t,返回当前线程t中的一个成员变量threadLocals。 那么我们继续取Thread类中取看一下成员变量threadLocals是什么:
1 | /* ThreadLocal values pertaining to this thread. This map is maintained |
实际上就是一个ThreadLocalMap,这个类型是ThreadLocal类的一个内部类,我们继续取看ThreadLocalMap的实现:
1 | /** |
可以看到ThreadLocalMap的Entry继承了WeakReference,并且使用ThreadLocal作为键值。 然后再继续看setInitialValue方法的具体实现:
1 | /** |
很容易了解,就是如果map不为空,就设置键值对,为空,再创建Map,看一下createMap的实现:
1 | /** |
至此,可能大部分朋友已经明白了ThreadLocal是如何为每个线程创建变量的副本的:
首先,在每个线程Thread内部有一个ThreadLocal.ThreadLocalMap类型的成员变量threadLocals,这个threadLocals就是用来存储实际的变量副本的,键值为当前ThreadLocal变量,value为变量副本(即T类型的变量)。
初始时,在Thread里面,threadLocals为空,当通过ThreadLocal变量调用get()方法或者set()方法,就会对Thread类中的threadLocals进行初始化,并且以当前ThreadLocal变量为键值,以ThreadLocal要保存的副本变量为value,存到threadLocals。
然后在当前线程里面,如果要使用副本变量,就可以通过get方法在threadLocals里面查找。
下面通过一个例子来证明通过ThreadLocal能达到在每个线程中创建变量副本的效果:
1 | public class Test { |
输出结果:
1 | 1 |
从这段代码的输出结果可以看出,在main线程中和thread1线程中,longLocal保存的副本值和stringLocal保存的副本值都不一样。最后一次在main线程再次打印副本值是为了证明在main线程中和thread1线程中的副本值确实是不同的。
总结一下:
如果想在get之前不需要调用set就能正常访问的话,必须重写initialValue()方法。因为在上面的代码分析过程中,我们发现如果没有先set的话,即在map中查找不到对应的存储,则会通过调用setInitialValue方法返回i,而在setInitialValue方法中,有一个语句是T value = initialValue(), 而默认情况下,initialValue方法返回的是null。
1 | /** |
看下面这个例子:
1 | public class Test { |
在main线程中,没有先set,直接get的话,运行时会报空指针异常。 但是如果改成下面这段代码,即重写了initialValue方法:
1 | public class Test { |
就可以直接不用先set而直接调用get了。
最常见的ThreadLocal使用场景为 用来解决 数据库连接、Session管理等。 如:
1 | private static ThreadLocal<Connection> connectionHolder |
在很多地方都会利用到hash表来提高查找效率。在Java的Object类中有一个方法:
1 | public native int hashCode(); |
public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }
modCount++;
addEntry(hash, key, value, i);
return null;
}1 | put方法是用来向HashMap中添加新的元素,从put方法的具体实现可知,会先调用hashCode方法得到该元素的hashCode值,然后查看table中是否存在该hashCode值,如果存在则调用equals方法重新确定是否存在该元素,如果存在,则更新value值,否则将新的元素添加到HashMap中。从这里可以看出,hashCode方法的存在是为了减少equals方法的调用次数,从而提高程序效率。 |
static inline intptr_t get_next_hash(Thread * Self, oop obj) { intptr_t value = 0 ; if (hashCode == 0) { // This form uses an unguarded global Park-Miller RNG, // so it’s possible for two threads to race and generate the same RNG. // On MP system we’ll have lots of RW access to a global, so the // mechanism induces lots of coherency traffic. value = os::random() ; } else if (hashCode == 1) { // This variation has the property of being stable (idempotent) // between STW operations. This can be useful in some of the 1-0 // synchronization schemes. intptr_t addrBits = intptr_t(obj) >> 3 ; value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ; } else if (hashCode == 2) { value = 1 ; // for sensitivity testing } else if (hashCode == 3) { value = ++GVars.hcSequence ; } else if (hashCode == 4) { value = intptr_t(obj) ; } else { // Marsaglia’s xor-shift scheme with thread-specific state // This is probably the best overall implementation – we’ll // likely make this the default in future releases. unsigned t = Self->_hashStateX ; t ^= (t << 11) ; Self->_hashStateX = Self->_hashStateY ; Self->_hashStateY = Self->_hashStateZ ; Self->_hashStateZ = Self->_hashStateW ; unsigned v = Self->_hashStateW ; v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ; Self->_hashStateW = v ; value = v ; }
value &= markOopDesc::hash_mask; if (value == 0) value = 0xBAD ; assert (value != markOopDesc::no_hash, “invariant”) ; TEVENT (hashCode: GENERATE) ; return value; }
1 | 该实现位于`hotspot/src/share/vm/runtime/synchronizer.cpp`文件下。 |
import java.util.HashMap; import java.util.HashSet; import java.util.Set; class People{ private String name; private int age;
public People(String name,int age) {
this.name = name;
this.age = age;
}
public void setAge(int age){
this.age = age;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
return this.name.equals(((People)obj).name) && this.age== ((People)obj).age;
}}
public class Main {
public static void main(String[] args) {
People p1 = new People("Jack", 12);
System.out.println(p1.hashCode());
HashMap<People, Integer> hashMap = new HashMap<People, Integer>();
hashMap.put(p1, 1);
System.out.println(hashMap.get(new People("Jack", 12)));
}}
1 | 在这里只重写了equals方法,也就说如果两个People对象,如果它的姓名和年龄相等,则认为是同一个人。这段代码本来的意愿是想这段代码输出结果为“1”,但是事实上它输出的是“null”。为什么呢?原因就在于**重写equals方法的同时忘记重写hashCode方法**。 |
public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; }
1 | 所以在hashmap进行get操作时,因为得到的hashcdoe值不同(注意,上述代码也许在某些情况下会得到相同的hashcode值,不过这种概率比较小,因为虽然两个对象的存储地址不同也有可能得到相同的hashcode值),所以导致在get方法中for循环不会执行,直接返回null。因此如果想上述代码输出结果为“1”,很简单,只需要重写hashCode方法,让equals方法和hashCode方法始终在逻辑上保持一致性。 |
@Override public int hashCode() { return name.hashCode()*37+age; }
1 | 这样一来的话,输出结果就为“1”了。 |
import java.util.HashMap; import java.util.HashSet; import java.util.Set;
class People{ private String name; private int age;
public People(String name,int age) {
this.name = name;
this.age = age;
}
public void setAge(int age){
this.age = age;
}
@Override
public int hashCode() {
// TODO Auto-generated method stub
return name.hashCode()*37+age;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
return this.name.equals(((People)obj).name) && this.age== ((People)obj).age;
}}
public class Main {
public static void main(String[] args) {
People p1 = new People("Jack", 12);
System.out.println(p1.hashCode());
HashMap<People, Integer> hashMap = new HashMap<People, Integer>();
hashMap.put(p1, 1);
p1.setAge(13);
System.out.println(hashMap.get(p1));
}}
1 | 这段代码输出的结果为“null”,因此,在设计hashCode方法和equals方法的时候,如果对象中的数据易变,则最好在equals方法和hashCode方法中不要依赖于该字段。 |
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}1 | 乍看一下就是简单的异或运算和右移运算,但是为什么要异或呢?为什么要移位呢?而且移位16? |
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
// 我们需要关注下面这一行
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}1 | 我们看看代码中注释下方的一行代码:first = tab[(n - 1) & hash])。 |
tab[(n - 1) & hash];
1 | 其中 n 是数组的长度。其实该算法的结果和模运算的结果是相同的。但是,对于现代的处理器来说,除法和求余数(模运算)是最慢的动作。 |
a % b == (b-1) & a ,当b是2的指数时,等式成立。
1 |
|
import sys
if len(sys.argv) <= 1: print(“python vv_hash.py property_name”) exit(0)
propertyName = sys.argv[1] if len(propertyName) == 0: print(“empty element name”) exit(0)
hashCode = 0 for i in range(0, len(propertyName)): hashCode = (31 * hashCode + ord(propertyName[i])) & 0xFFFFFFFF if hashCode > 0x7FFFFFFF: hashCode = hashCode - 0x100000000 print(“hash code: %d” % (hashCode)) ```