混合就是把两种颜色混在一起。具体一点,就是把某一像素位置原来的颜色和将要画上去的颜色,通过某种方式混在一起,从而实现特殊的效果。
假设我们需要绘制这样一个场景:透过红色的玻璃去看绿色的物体,那么可以先绘制绿色的物体,再绘制红色玻璃。在绘制红色玻璃的时候,利用“混合”功能,把将要绘制上去的红色和原来的绿色进行混合,于是得到一种新的颜色,看上去就好像玻璃是半透明的。
要使用OpenGL的混合功能,只需要调用:glEnable(GL_BLEND);即可。要关闭OpenGL的混合功能,只需要调用:glDisable(GL_BLEND);即可。
注意: 只有在RGBA模式下,才可以使用混合功能,颜色索引模式下是无法使用混合功能的。
1.源因子和目标因子
混合需要把原来的颜色和将要画上去的颜色找出来,经过某种方式处理后得到一种新的颜色。这里把将要画上去的颜色称为“源颜色”,把原来的颜色称为“目标颜色”。
OpenGL 会把源颜色和目标颜色各自取出,并乘以一个系数(源颜色乘以的系数称为“源因子”,目标颜色乘以的系数称为“目标因子”),然后相加,这样就得到了新的颜 色。(也可以不是相加,新版本的OpenGL可以设置运算方式,包括加、减、取两者中较大的、取两者中较小的、逻辑运算等)
下面用数学公式来表达一下这个运算方式。假设源颜色的四个分量(指红色,绿色,蓝色,alpha值)是(Rs, Gs, Bs, As),目标颜色的四个分量是(Rd, Gd, Bd, Ad),又设源因子为(Sr, Sg, Sb, Sa),目标因子为(Dr, Dg, Db, Da)。则混合产生的新颜色可以表示为:
(Rs*Sr+Rd*Dr, Gs*Sg+Gd*Dg, Bs*Sb+Bd*Db, As*Sa+Ad*Da)
如果颜色的某一分量超过了1.0,则它会被自动截取为1.0,不需要考虑越界的问题。
源因子和目标因子是可以通过glBlendFunc函数来进行设置的。glBlendFunc有两个参数,前者表示源因子,后者表示目标因子。这两个参数可以是多种值,下面介绍比较常用的几种。
- GL_ZERO:表示使用0.0作为因子,实际上相当于不使用这种颜色参与混合运算。
- GL_ONE:表示使用1.0作为因子,实际上相当于完全的使用了这种颜色参与混合运算。
- GL_SRC_ALPHA:表示使用源颜色的alpha值来作为因子。
- GL_DST_ALPHA:表示使用目标颜色的alpha值来作为因子。
- GL_ONE_MINUS_SRC_ALPHA:表示用1.0减去源颜色的alpha值来作为因子。
- GL_ONE_MINUS_DST_ALPHA:表示用1.0减去目标颜色的alpha值来作为因子。
- GL_SRC_COLOR: 把源颜色的四个分量分别作为因子的四个分量
- GL_ONE_MINUS_SRC_COLOR
- GL_DST_COLOR
- GL_ONE_MINUS_DST_COLOR GL_SRC_COLOR与GL_ONE_MINUS_SRC_COLOR在OpenGL旧版本中只能用于设置目标因子,GL_DST_COLOR与GL_ONE_MINUS_DST_COLOR在OpenGL 旧版本中只能用于设置源因子。新版本的OpenGL则没有这个限制,并且支持新的GL_CONST_COLOR(设定一种常数颜色,将其四个分量分别作为 因子的四个分量)、GL_ONE_MINUS_CONST_COLOR、GL_CONST_ALPHA、 GL_ONE_MINUS_CONST_ALPHA。另外还有GL_SRC_ALPHA_SATURATE。新版本的OpenGL还允许颜色的alpha 值和RGB值采用不同的混合因子。
2.模式示例
- 如果设置了glBlendFunc(GL_ONE, GL_ZERO);,则表示完全使用源颜色,完全不使用目标颜色,因此画面效果和不使用混合的时候一致(当然效率可能会低一点点)。如果没有设置源因子和目标因子,则默认情况就是这样的设置。
- 如果设置了glBlendFunc(GL_ZERO, GL_ONE);,则表示完全不使用源颜色,因此无论你想画什么,最后都不会被画上去了。(但这并不是说这样设置就没有用,有些时候可能有特殊用途)
- 如果设置了glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);,则表示源颜色乘以自身的alpha 值,目标颜色乘以1.0减去源颜色的alpha值,这样一来,源颜色的alpha值越大,则产生的新颜色中源颜色所占比例就越大,而目标颜色所占比例则减 小。这种情况下,我们可以简单的将源颜色的alpha值理解为“不透明度”。这也是混合时最常用的方式。
- 如果设置了glBlendFunc(GL_ONE, GL_ONE);,则表示完全使用源颜色和目标颜色,最终的颜色实际上就是两种颜色的简单相加。例如红色(1, 0, 0)和绿色(0, 1, 0)相加得到(1, 1, 0),结果为黄色。 注意: 所谓源颜色和目标颜色,是跟绘制的顺序有关的。假如先绘制了一个红色的物体,再在其上绘制绿色的物体。则绿色是源颜色,红色是目标颜色。如果顺序反过来,则 红色就是源颜色,绿色才是目标颜色。在绘制时,应该注意顺序,使得绘制的源颜色与设置的源因子对应,目标颜色与设置的目标因子对应。
3.对两种示例模式的具体解释:
模式一:
1 | GLES20.glEnable(GLES20.GL_BLEND); |
模式二:
1 | GLES20.glEnable(GLES20.GL_BLEND); |
模式一是传统的alpha通道混合,这种模式下颜色和alpha值是分立的,rgb决定颜色,alpha决定..(英文是决定how solid it is 水平有限找不到准确的中文来表达)
在数学上表达式是:blend(source, dest) = (source.rgb * source.a) + (dest.rgb * (1 – source.a)).要注意的是这种模式下,透明只跟alpha有关,跟rgb值无关,一个透明的颜色,不透明的颜色有相同的rgb值,只要alpha=0即可。
模式二是alpha预乘的混合(Premultiplied Alpha Blending),这种模式下rgb与alpha是联系在一起的,数学上的表达式是
blend(source, dest) = source.rgb + (dest.rgb * (1 – source.a)),在这种模式下,透明的表示是rgb值都为0.
4.EGLSurface背景透明设置
在OpenGL绘制中,除了设置混色外,还要设置EGLSurface配置支持Alpha,如果不设置EGL相关的EGLSurface支持透明,就算OpenGL函数中开启混色,绘制完成后仍是有黑色背景.
4.1GLSurfaceView
在onSurfaceCreated里,调用GLES20.glClearColor(0f, 0f, 0f, 0f);alpha为0,即透明。
然后,对surfaceview要作一定处理:
1 | mGLSurfaceView.setEGLConfigChooser(8, 8, 8, 8, 16, 0); |
4.2SurfaceTexture或Surface构造的Surface
EGL14.eglChooseConfig中config数组增加EGL10.EGL_ALPHA_SIZE配置:
1 | int[] CONFIG_RGBA = { |
5.实现三维混合
在进行三维场景的混合时必须注意的是深度缓冲。
深度缓冲是这样一段数据,它记录了每一个像素距离观察者有多近。在启用深度缓冲测试的情况下,如果将要绘制的像素比原来的像素更近,则像素将被绘制。否则,像素就会被忽略掉,不进行绘制。这在绘制不透明的物体时非常有用——不管是先绘制近的物体再绘制远的物体,还是先绘制远的物体再绘制近的物体,或者干脆以 混乱的顺序进行绘制,最后的显示结果总是近的物体遮住远的物体。 然而在你需要实现半透明效果时,发现一切都不是那么美好了。如果你绘制了一个近距离的半透明物体,则它在深度缓冲区内保留了一些信息,使得远处的物体将无法再被绘制出来。虽然半透明的物体仍然半透明,但透过它看到的却不是正确的内容了。 要 解决以上问题,需要在绘制半透明物体时将深度缓冲区设置为只读,这样一来,虽然半透明物体被绘制上去了,深度缓冲区还保持在原来的状态。如果再有一个物体 出现在半透明物体之后,在不透明物体之前,则它也可以被绘制(因为此时深度缓冲区中记录的是那个不透明物体的深度)。以后再要绘制不透明物体时,只需要再 将深度缓冲区设置为可读可写的形式即可。怎么绘制一个一部分半透明一部分不透明的物体?这个好办,只需要把物体分为两个部分,一部分全是半透明 的,一部分全是不透明的,分别绘制就可以了。 即使使用了以上技巧,我们仍然不能随心所欲的按照混乱顺序来进行绘制。必须是先绘制不透明的物体,然 后绘制透明的物体。否则,假设背景为蓝色,近处一块红色玻璃,中间一个绿色物体。如果先绘制红色半透明玻璃的话,它先和蓝色背景进行混合,则以后绘制中间 的绿色物体时,想单独与红色玻璃混合已经不能实现了。 总结起来,绘制顺序就是:首先绘制所有不透明的物体。如果两个物体都是不透明的,则谁先谁后 都没有关系。然后,将深度缓冲区设置为只读。接下来,绘制所有半透明的物体。如果两个物体都是半透明的,则谁先谁后只需要根据自己的意愿(注意了,先绘制 的将成为“目标颜色”,后绘制的将成为“源颜色”,所以绘制的顺序将会对结果造成一些影响)。最后,将深度缓冲区设置为可读可写形式。 调用glDepthMask(GL_FALSE);可将深度缓冲区设置为只读形式。调用glDepthMask(GL_TRUE);可将深度缓冲区设置为可读可写形式。
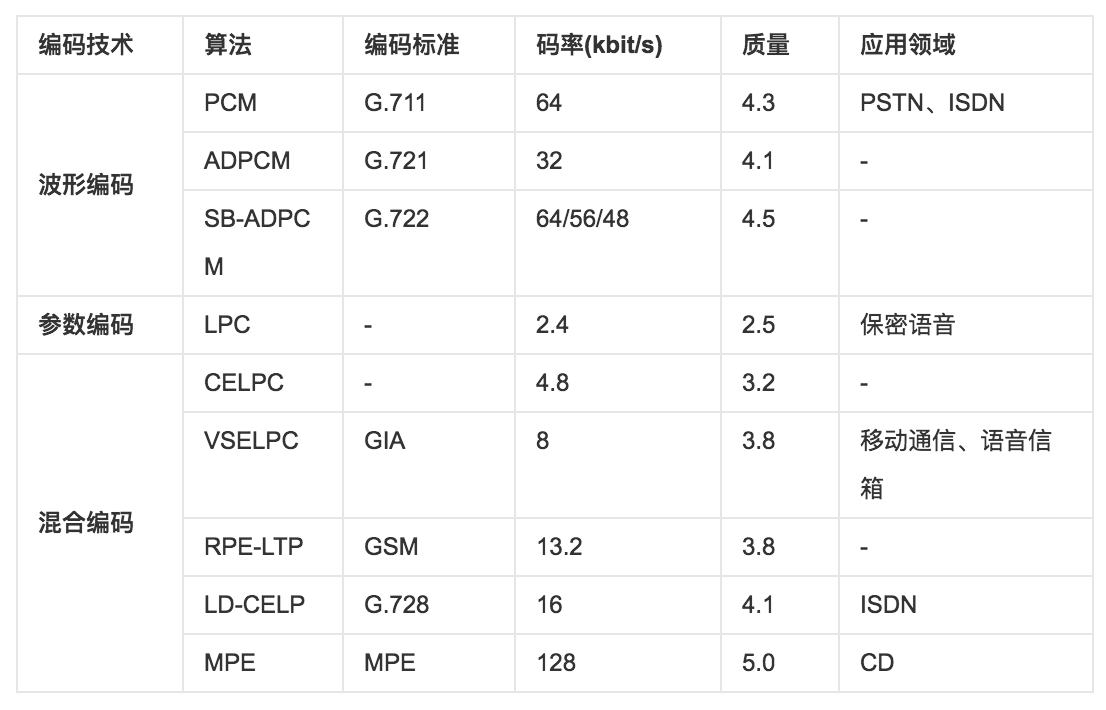 说明:质量评价共五个等级(1、2、3、4、5),其中5.0为最高分。
上表中各种算法、应用领域中缩略语的中文和英文全称参见下面说明。
说明:质量评价共五个等级(1、2、3、4、5),其中5.0为最高分。
上表中各种算法、应用领域中缩略语的中文和英文全称参见下面说明。 物体的颜色是丰富多彩的,任何一种颜色和这3种基色之间的关系可以用下面的配色方程式来描述:
F(物体颜色)=R(红色的百分比) + G(绿色的百分比) + B(蓝色的百分比)
物体的颜色是丰富多彩的,任何一种颜色和这3种基色之间的关系可以用下面的配色方程式来描述:
F(物体颜色)=R(红色的百分比) + G(绿色的百分比) + B(蓝色的百分比)