查看内存方式
Running services
通过手机上Running services的Activity查看,可以通过Setting->Applications->Running services进。 PS.其实现在有很多查看内存管理的第三方应用了,例如手机管家
用ActivityManager的getMemoryInfo(ActivityManager.MemoryInfo outInfo)
ActivityManager.getMemoryInfo()主要是用于得到当前系统剩余内存的及判断是否处于低内存运行。
1 | private void displayBriefMemory() { |
ActivityManager.getMemoryInfo()是用ActivityManager.MemoryInfo返回结果,而不是Debug.MemoryInfo,他们不一样的。 ActivityManager.MemoryInfo只有三个Field:
- availMem:表示系统剩余内存
- lowMemory:它是boolean值,表示系统是否处于低内存运行
- hreshold:它表示当系统剩余内存低于好多时就看成低内存运行
在代码中使用Debug的getMemoryInfo(Debug.MemoryInfo memoryInfo)或ActivityManager的MemoryInfo[] getProcessMemoryInfo(int[] pids)
该方式得到的MemoryInfo所描述的内存使用情况比较详细.数据的单位是KB.
MemoryInfo的Field如下
- dalvikPrivateDirty: The private dirty pages used by dalvik。
- dalvikPss :The proportional set size for dalvik.
- dalvikSharedDirty :The shared dirty pages used by dalvik.
- nativePrivateDirty :The private dirty pages used by the native heap.
- nativePss :The proportional set size for the native heap.
- nativeSharedDirty :The shared dirty pages used by the native heap.
- otherPrivateDirty :The private dirty pages used by everything else.
- otherPss :The proportional set size for everything else.
- otherSharedDirty :The shared dirty pages used by everything else.
- Android和Linux一样有大量内存在进程之间进程共享。某个进程准确的使用好多内存实际上是很难统计的。
- 因为有paging out to disk(换页),所以如果你把所有映射到进程的内存相加,它可能大于你的内存的实际物理大小。
- dalvik:是指dalvik所使用的内存。
- native:是被native堆使用的内存。应该指使用C\C++在堆上分配的内存。
- other:是指除dalvik和native使用的内存。但是具体是指什么呢?至少包括在C\C++分配的非堆内存,比如分配在栈上的内存。puzlle!
- private:是指私有的。非共享的。
- share:是指共享的内存。
- PSS:实际使用的物理内存(比例分配共享库占用的内存)
- Pss:它是把共享内存根据一定比例分摊到共享它的各个进程来计算所得到进程使用内存。网上又说是比例分配共享库占用的内存,那么至于这里的共享是否只是库的共享,还是不清楚。
- PrivateDirty:它是指非共享的,又不能换页出去(can not be paged to disk )的内存的大小。比如Linux为了提高分配内存速度而缓冲的小对象,即使你的进程结束,该内存也不会释放掉,它只是又重新回到缓冲中而已。
- SharedDirty:参照PrivateDirty我认为它应该是指共享的,又不能换页出去(can not be paged to disk )的内存的大小。比如Linux为了提高分配内存速度而缓冲的小对象,即使所有共享它的进程结束,该内存也不会释放掉,它只是又重新回到缓冲中而已。
具体代码请参考实例1
- 注意1:MemoryInfo所描述的内存使用情况都可以通过命令adb shell “dumpsys meminfo %curProcessName%” 得到。
- 注意2:如果想在代码中同时得到多个进程的内存使用或非本进程的内存使用情况请使用ActivityManager的MemoryInfo[] getProcessMemoryInfo(int[] pids),否则Debug的getMemoryInfo(Debug.MemoryInfo memoryInfo)就可以了。
- 注意3:可以通过ActivityManager的List<ActivityManager.RunningAppProcessInfo> getRunningAppProcesses()得到当前所有运行的进程信息。ActivityManager.RunningAppProcessInfo中就有进程的id,名字以及该进程包括的所有apk包名列表等。
- 注意4:数据的单位是KB.
方式4、使用Debug的getNativeHeapSize (),getNativeHeapAllocatedSize (),getNativeHeapFreeSize ()方法。
该方式只能得到Native堆的内存大概情况,数据单位为字节。
static long getNativeHeapAllocatedSize()
Returns the amount of allocated memory in the native heap.
返回的是当前进程navtive堆中已使用的内存大小 static long getNativeHeapFreeSize()
Returns the amount of free memory in the native heap.
返回的是当前进程navtive堆中已经剩余的内存大小
static long getNativeHeapSize()
Returns the size of the native heap.
返回的是当前进程navtive堆本身总的内存大小
示例代码:
1 | Log.i(tag,"NativeHeapSizeTotal:"+(Debug.getNativeHeapSize()>>10)); |
注意:DEBUG中居然没有与上面相对应的关于dalvik的函数。
使用”adb shell cat /proc/meminfo” 命令。
该方式只能得出系统整个内存的大概使用情况。
MemTotal: 395144 kB
MemFree: 184936 kB
Buffers: 880 kB
Cached: 84104 kB
SwapCached: 0 kB
……………………………………………………………………………………
MemTotal :可供系统和用户使用的总内存大小 (它比实际的物理内存要小,因为还有些内存要用于radio, DMA buffers, 等).
MemFree:剩余的可用内存大小。这里该值比较大,实际上一般Android system 的该值通常都很小,因为我们尽量让进程都保持运行,这样会耗掉大量内存。
Cached: 这个是系统用于文件缓冲等的内存. 通常systems需要20MB 以避免bad paging states;。当内存紧张时,the Android out of memory killer将杀死一些background进程,以避免他们消耗过多的cached RAM ,当然如果下次再用到他们,就需要paging. 那么是说background进程的内存包含在该项中吗?
使用“adb shell ps -x”命令
该方式主要得到的是内存信息是VSIZE 和RSS。
USER PID PPID VSIZE RSS WCHAN PC NAME
…………………….省略……………………………
app_70 3407 100 267104 22056 ffffffff afd0eb18 S com.teleca.robin.test (u:55, s:12)
app_7 3473 100 268780 21784 ffffffff afd0eb18 S com.android.providers.calendar (u:16, s:8)
radio 3487 100 267980 21140 ffffffff afd0eb18 S com.osp.app.signin (u:11, s:12)
system 3511 100 273232 22024 ffffffff afd0eb18 S com.android.settings (u:11, s:4)
app_15 3546 100 267900 20300 ffffffff afd0eb18 S com.sec.android.providers.drm (u:15, s:6)
app_59 3604 100 272028 22856 ffffffff afd0eb18 S com.wssyncmldm (u:231, s:54)
root 4528 2 0 0 c0141e4c 00000000 S flush-138:13 (u:0, s:0)
root 4701 152 676 336 c00a68c8 afd0e7cc S /system/bin/sh (u:0, s:0)
root 4702 4701 820 340 00000000 afd0d8bc R ps (u:0, s:5)
VSZIE:意义暂时不明。
dumpsys meminfo
adb shell dumpsys meminfo -a <process id>/<process name>来查看一个进程的memory。截图如下:
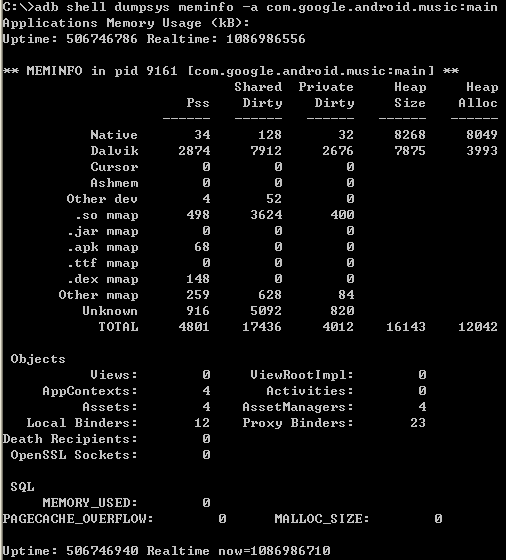
Naitve Heap Size: 从mallinfo usmblks获得,代表最大总共分配空间
Native Heap Alloc: 从mallinfo uorblks获得,总共分配空间
Native Heap Free: 从mallinfo fordblks获得,代表总共剩余空间
Native Heap Size 约等于Native Heap Alloc + Native Heap Free
mallinfo是一个C库, mallinfo 函数提供了各种各样的通过C的malloc()函数分配的内存的统计信息。
Dalvik Heap Size:从Runtime totalMemory()获得,Dalvik Heap总共的内存大小。
Dalvik Heap Alloc: Runtime totalMemory()-freeMemory() ,Dalvik Heap分配的内存大小。
Dalvik Heap Free:从Runtime freeMemory()获得,Dalvik Heap剩余的内存大小。
Dalvik Heap Size 约等于Dalvik Heap Alloc + Dalvik Heap Free
OtherPss, include Cursor,Ashmem, Other Dev, .so mmap, .jar mmap, .apk mmap, .ttf mmap, .dex mmap, Other mmap, Unkown统计信息都可以在process的smap文件看到。
Objects and SQL 信息都是从Android Debug信息中获得。
1 | 其他类型 smap 路径名称 描述 |
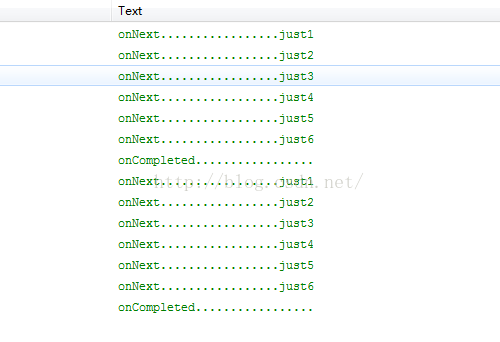 尽管打印的结果一样,但是它们不是取自同一个Observable的数据
尽管打印的结果一样,但是它们不是取自同一个Observable的数据
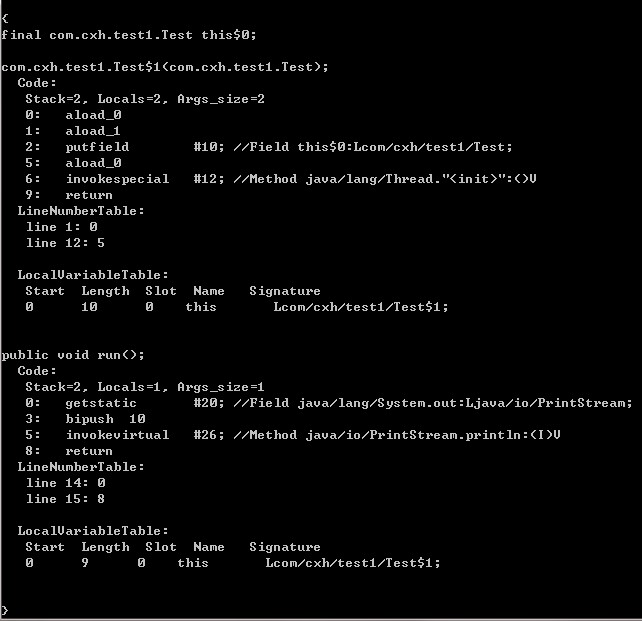 我们看到在run方法中有一条指令:
我们看到在run方法中有一条指令: