前言
mars 是微信官方使用 C++ 编写的业务性无关、平台性无关的终端基础组件,目前在微信 Android、iOS、Windows、Mac、Windows Phone 等多个平台中使用,并正在筹备开源,它主要包含以下几个独立的部分:
- COMM:基础库,包括 socket、线程、消息队列、协程等基础工具;
- XLOG:通用日志模块,充分考虑移动终端的特点,提供高性能、高可用、安全性、容错性的日志功能;(详情点击:高性能日志模块xlog )
- SDT:网络诊断模块;
- STN:信令传输网络模块,负责终端与服务器的小数据信令通道。包含了微信终端在移动网络上的大量优化经验与成果,经历了微信海量用户的考验。
本篇文章将为大家介绍 STN(信令传输网络模块),由于 STN 的复杂性,该模块将被分解为多个篇章进行介绍,本文主要内容为微信中关于读写超时的思考与设计。
读写超时与设计目标
TCP/IP中的超时设计
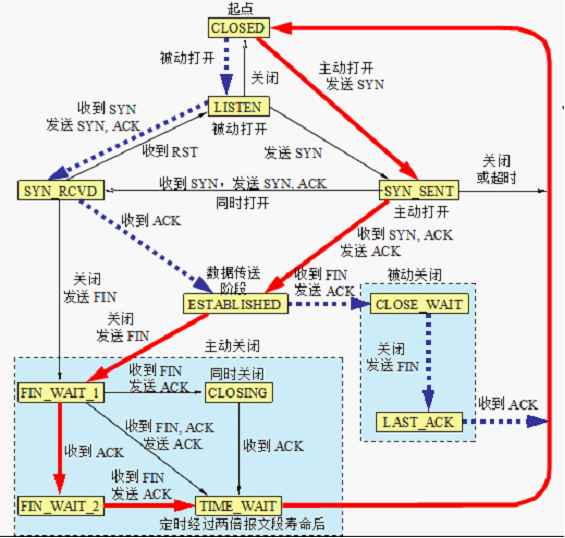
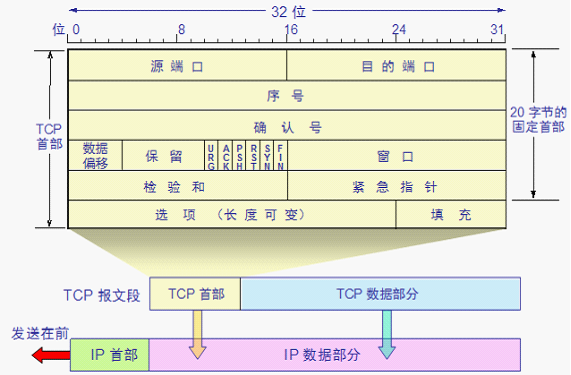
微信信令通信主要使用 TCP/IP 协议,数据经过应用层、传输层、网络层、链路层(见图1)。其中,链路层与传输层,协议提供了超时重传的机制。
链路层的超时与重传
在链路层,一般使用混合自动重传请求(即 HARQ)。HARQ 是一种结合 FEC(前馈式错误修正)与 ARQ(自动重传请求)的技术,原理如图2所示。
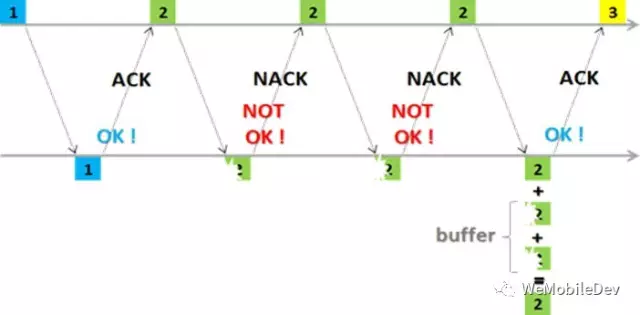
通过使用确认和超时这两个机制,链路层在不可靠物理设备的基础上实现可靠的信息传输。这个方案需要手机和 RNC 都支持,目前在 EDGE、HSDPA、HSUPA、UMTS和 LTE 上都已实现支持。
传输层的超时与重传
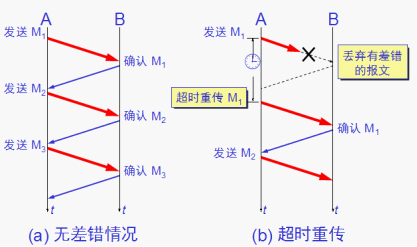
传输层(即 TCP 层)提供可靠的传输,然而,TCP 层依赖的链路本身是不可靠的,TCP 是如何在不可靠的环境中提供可靠服务的呢?答案是超时和重传。TCP 在发送数据时设置一个定时器,当定时器溢出还没有收到 ACK,则重传该数据。因此,超时与重传的关键之处在于如何决定定时器间隔与重传频率。
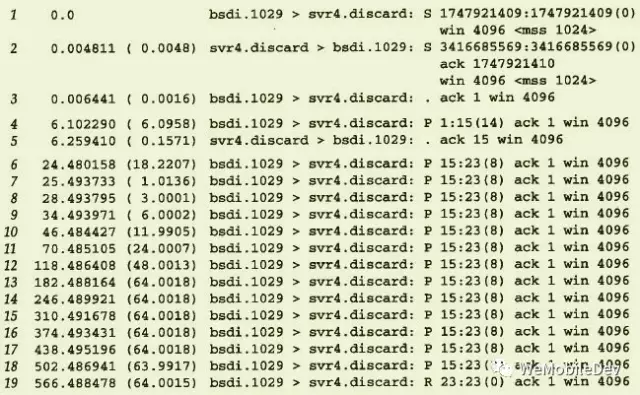
传统 Unix 实现中,定时器的间隔取决于数据的往返时间(即 RTT),根据 RTT 进行一定的计算得到重传超时间隔(即 RTO)。由于网络路由、流量等的变化,RTT 是经常发生变化的,RTT 的测量也极为复杂(平滑算法、Karn 算法、Jacbson 算法等)。在《TCP/IP详解》中,实际测量的重传机制如图3所示,重传的时间间隔,取整后分别为1、3、6、12、24、48和多个64秒。这个倍乘的关系被称为“指数退避”。
在移动终端中,RTO 的设计以及重试频率的设计是否与传统实现一致呢?对此我们进行了实测,实测数据如下:
图4所示为OPPO手机TCP超时重传的间隔,依次为[ 0.25s,0.5s,1s,2s,4s,8s,16s,32s,64s,64s,64s …]:

而 SamSung 中 TCP 超时重传的间隔依次为[0.42s, 0.9s, 1.8s, 3.7s, 7.5s, 15s, 30s, 60s, 120s, 120s …],见图5。
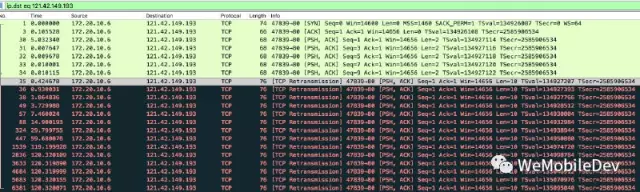
经过多次实际测试我们可以看出虽然由于不同厂商的 Android 系统实现,RTO 的值可能会有不同的设定,但都基本符合“指数退避”原则。
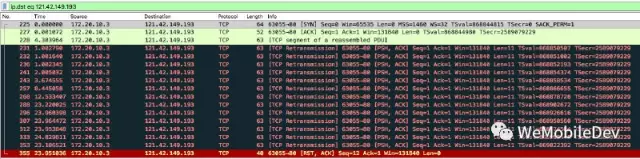
接下来再看 iOS 系统中,TCP RTO 的实验数据,图6所示为实验中第一次的数据[ 1s,1s,1s,2s,4.5s,9s,13.5s,26s,26s … ]。

上面的数据看起来并不完全符合指数退避,开始阶段的重试会较为频繁且 RTO 最终固定在 26s 这一较小的值上。
进行第二次测试后发现数据有了新的变化[1s,1s,1s,2s,3.5s,8.5s,12.5s,24s,24s …],如图7所示。
RTO 终值由26秒缩减至24秒,最终经过多次测试并未发现 iOS 中 TCP RTO 的规律,但可以看出 iOS 确实采用了较为激进的超时时间设定,对重试更为积极。
读写超时的目标
通过上述的调研与实验,可以发现在 TCP/IP 中,协议栈已经帮助我们进行了超时与重传的控制。并且在 Android、iOS 的移动操作系统中进行了优化,使用了更为积极的策略,以适应移动网络不稳定的特征。
那是否意味着我们的应用层已经不需要超时与重传的控制了呢?其实不然。在链路层,HARQ 提供的是节点之间每一数据帧的可靠传输;在传输层,TCP 超时重传机制提供的是端与端之间每个 TCP 数据包的可靠传输;同理,在微信所处的应用层中,我们仍然需要提供以“请求”为粒度的可靠传输。
那么,应用层的超时重传机制应该提供怎样的服务呢?
首先,我们来看一下应用层重传的做法。在应用层中,重传的做法是:断掉当前连接,重新建立连接并发送请求。这种重传方式能带来怎样的作用呢?回顾 TCP 层的超时重传机制可以发现,当发生超时重传时,重传的间隔以“指数退避”的规律急剧上升。在 Android 系统中,直到16分钟,TCP 才确认失败;在 iOS 系统中,直到1分半到3分半之间,TCP 才确认失败。这些数值在大部分应用中都是不为“用户体验”所接受的。因此,应用层的超时重传的目标首先应是: 在用户体验的接受范围内,尽可能地提高成功率 尽可能地增加成功率,是否意味着在有限的时间内,做尽可能多的重试呢?其实不然。当网络为高延迟/低速率的网络时,较快的应用层重传会导致“请求”在这种网络下很难成功。因此,应用层超时重传的目标二: 保障弱网络下的可用性 TCP连接是有固定物理线路的连接,当已 Connect 的线路中,如果中间设备出现较大波动或严重拥塞,即使在限定时间内该请求能成功,但带来的却是性能低下,反应迟钝的用户体验。通过应用层重连,期待的目标三是: 具有网络敏感性,快速的发现新的链路
我们总结应用层超时重传,可以带来以下作用:
- 减少无效等待时间,增加重试次数:当 TCP 层的重传间隔已经太大的时候,断连重连,使得 TCP 层保持积极的重连间隔,提高成功率;
- 切换链路:当链路存在较大波动或严重拥塞时,通过更换连接(一般会顺带更换IP&Port)获得更好的性能。
微信读写超时
方案一:总读写超时
在TCP层的超时重传设计中,超时间隔取决于RTT,RTT即TCP包往返的时间。同理,在微信的早期设计中,我们分析应用层“请求”的往返时间,将其RTT分解为:
- 请求发送耗时 - 类比TCP包传输耗时;
- 响应信令接收耗时 - 类比ACK传输耗时;
- 服务器处理请求耗时 - TCP接收端接收和处理数据包的时间相对固定,而微信服务器由于信令所属业务的不同,逻辑处理的耗时会差异明显,所以无法类比;
- 等待耗时 - 受应用中请求并发数影响。
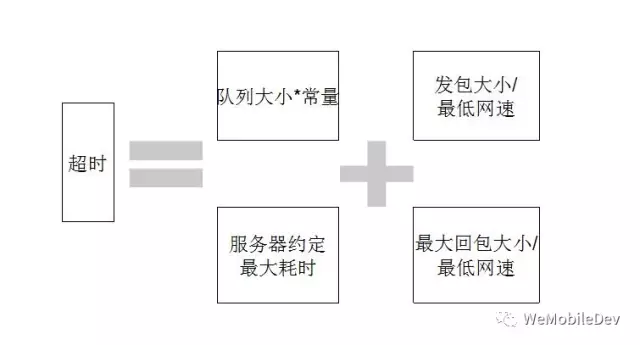
因此,我们提出了应用层的总读写超时如图8所示,最低网速根据不同的网络取不同的值。
方案二:分步的读写超时
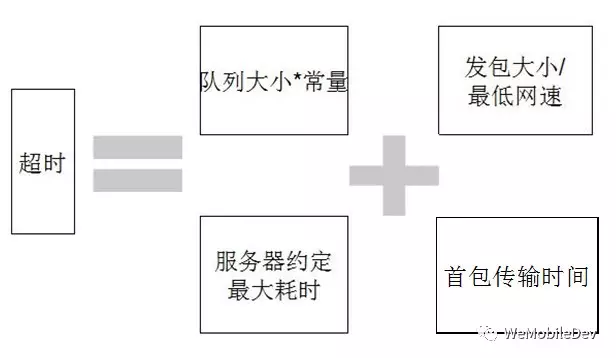
在实际的使用过程中,我们发现这仅仅是一个可用的方案,并不是一个高性能的解决方案:超时时长的设置使用了差网络下、完整的完成单次信令交互的时间估值。这使得超时时间过长,在网络波动或拥塞时,无法敏感地发现问题并重试。进一步分析可以发现,我们无法预知服务器回包的大小,因此使用了最大的回包进行估算(微信中目前最大回包可到 128KB)。然而,TCP 传输中当发送数据大于 MSS 时,数据将被分段传输,分段到达接收端后重新组合。如果服务器的回包较大,客户端可能会收到多个数据段。因此,我们可以对首个数据分段的到达时间进行预期,从而提出首包超时,如图9所示。
首包超时缩短了发现问题的周期,但是我们发现如果首个数据分段按时到达,而后续数据包丢失的情况下,仍然要等待整个读写超时才能发现问题。为此我们引入了包包超时,即两个数据分段之间的超时时间。因为包包超时在首包超时之后,这个阶段已经确认服务器收到了请求,且完成了请求的处理,因此不需要计算等待耗时、请求传输耗时、服务器处理耗时,只需要估算网络的 RTT。
在目前方案中,使用了不同网络下的固定 RTT。由于有了“首包已收到”的上下文,使得包包超时的间隔大大缩短,从而提高了对网络突然波动、拥塞、突发故障的敏感性,使得应用获得较高的性能。
方案三:动态的读写超时
在上述的方案中,总读写超时、首包超时都使用了一些估值,使得这两个超时是较大的值。假如我们能获得实时的动态网速等,我们能获得更好的超时机制,如图10所示。
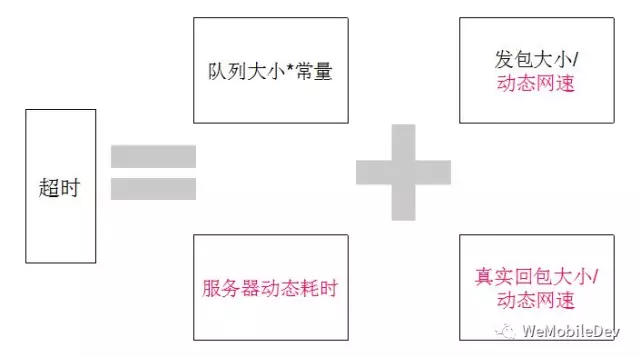
但是,理想是丰满的,现实是残酷的:
- 动态网速需要通过工具方法测定,实时性要求高,并且要考虑网络波动的影响;
- 服务器动态耗时需要服务器下发不同业务信令的处理耗时;
- 真实回包大小则只能靠服务器通知。
上述的三种途径对客户端和服务器都是巨大的流量、性能的消耗,所以动态化这些变量看起来并不可行。
因此,这里需要换个角度思考动态优化,手机的网络状况可以大概地归为优质、正常、差三种情况,针对三种网络状况进行不同程度的调整,也是动态优化的一种手段。这里选择优质网络状况进行分析:
- 如何判定网络状况好?网速快、稳定,网络模块中与之等价的是能够短时间完成信令收发,并且能够连续长时间地完成短时间内信令收发。
- 即使出现网络波动,也可以预期会很快恢复。
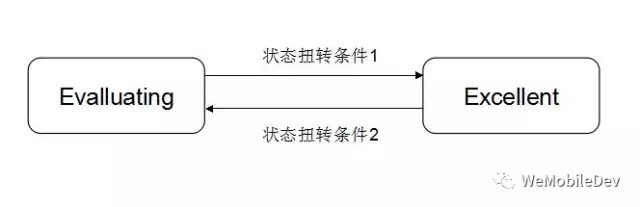
根据对网络状况好的分析,我们可以做出这样的优化(如图11所示):
- 将客户端网络环境区分为优良(Excellent)、评估(Evaluating)两种状态;
- 网速快、稳定就是条件1,信令失败或网络类型切换是条件2。
进入Exc状态后,就缩短信令收发的预期,即减小首包超时时间,这样做的原因是我们认为用户的网络状况好,可以设置较短的超时时间,当遇到网络波动时预期它能够快速恢复,所以可以尽快超时然后进行重试,从而改善用户体验。
总结
虽然 TCP/IP 协议栈中的链路层、传输层都已经提供了超时重传,保障了传输的可靠性。但应用层有着不同的可靠性需求,从而需要额外的应用层超时重传机制来保障应用的高性能、高可用。应用层超时重传的设计目标,笔者从自身经验出发,总结为:
- 在用户体验的接受范围内,尽可能地提高成功率;
- 保障弱网络下的可用性;
- 具有网络敏感性,快速地发现新的链路。
依从这些目标,mars STN 的超时重传机制在使用中不断的精细化演进,使用了包含总读写超时、首包超时、包包超时、动态超时等多种方案的综合。即使如此,STN 的超时重传机制也有着不少的缺点与局限性,例如相对适用于小数据传输的信令通道、局限于一来一回的通信模式等。mars STN 也会不断发现新的问题持续演进,并且所有的演进都将在微信的海量用户中进行验证。同时也期待随着 mars STN 的开源,能收获更多、更广的经验交流、问题反馈、新想法的碰撞等。
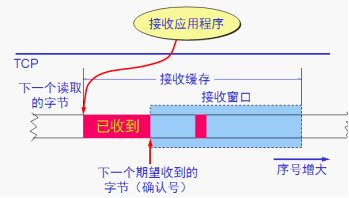
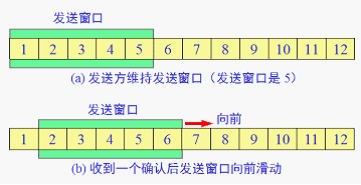
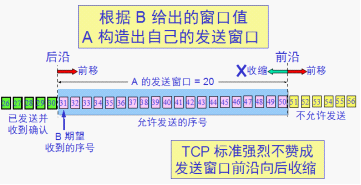
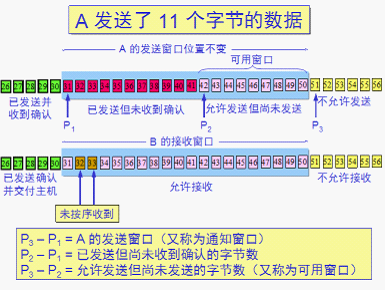
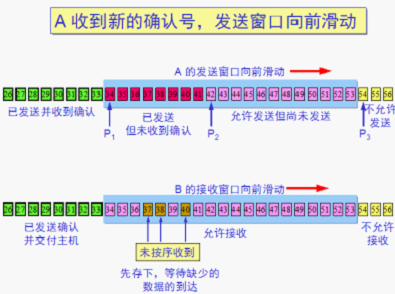

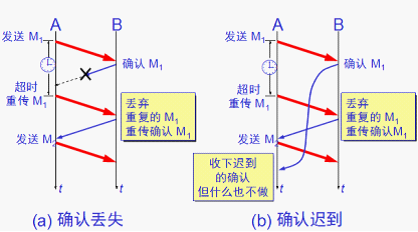 RTT = 传播时间+接收端处理时间+路由器的排队时间(变化较大反应当前网络拥塞情况)
RTT = 传播时间+接收端处理时间+路由器的排队时间(变化较大反应当前网络拥塞情况)
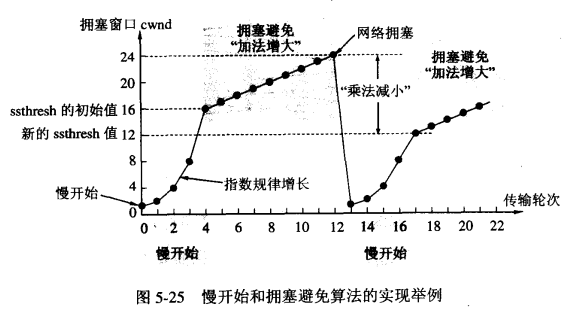 其目的是: 拥塞发生时循序减少主机发送到网络的报文数,使得这时路由器有足够的时间消化积压的报文。
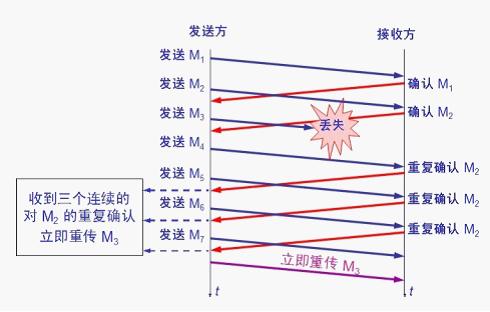
其目的是: 拥塞发生时循序减少主机发送到网络的报文数,使得这时路由器有足够的时间消化积压的报文。 其目的是: 减少因为拥塞导致的数据包丢失的重传时间,避免无用的数据到网络
其目的是: 减少因为拥塞导致的数据包丢失的重传时间,避免无用的数据到网络 防止丢包导致发送端停留在上次收到的接收窗口大小为0的情况:
防止丢包导致发送端停留在上次收到的接收窗口大小为0的情况: