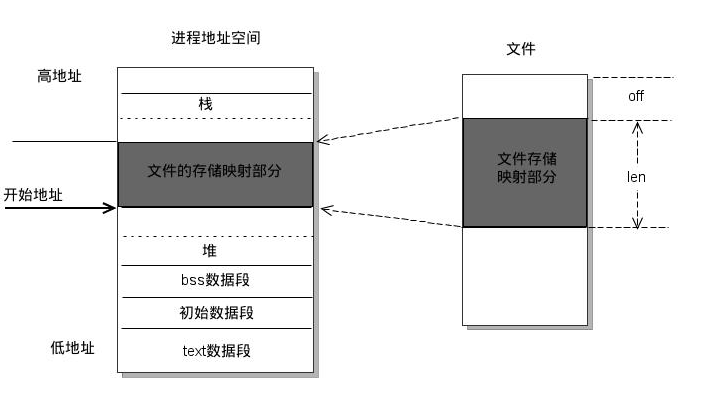
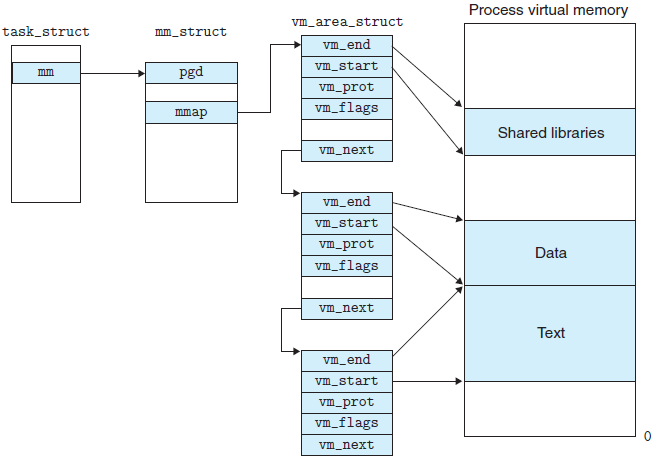
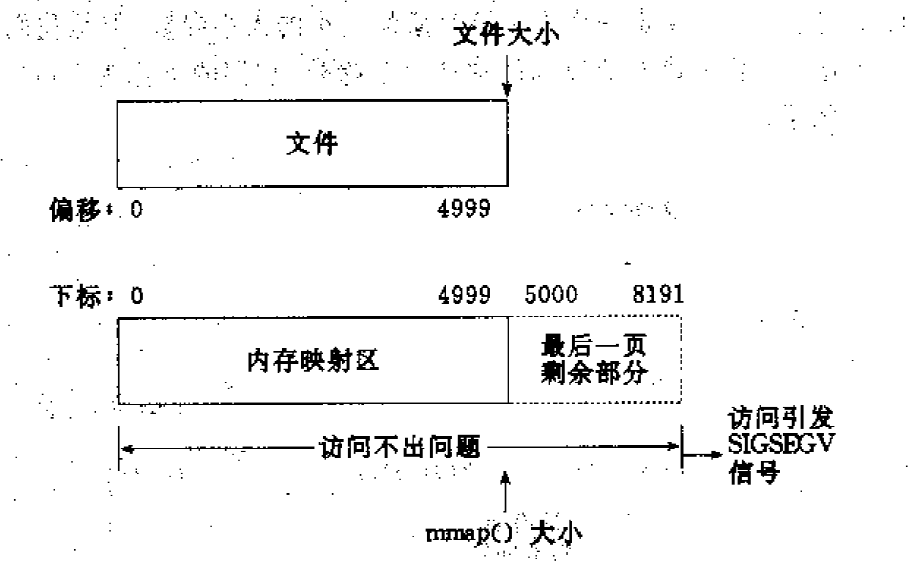
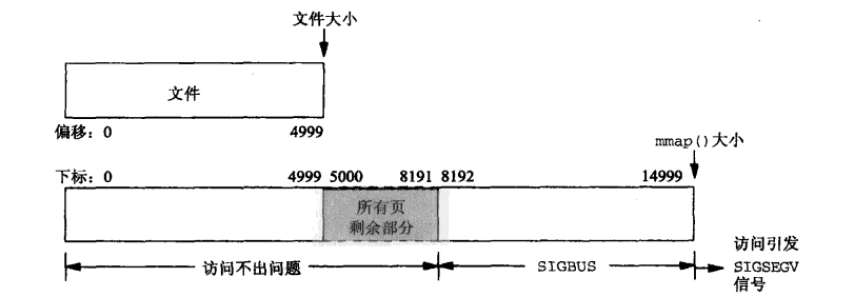
pip install -r requirements.txt conda install –yes –file requirements.txt
pip批量导出包含环境中所有组件的requirements.txt文件
1 | pip freeze > requirements.txt |
pip批量安装requirements.txt文件中包含的组件依赖
1 | pip install -r requirements.txt |
conda批量导出包含环境中所有组件的requirements.txt文件
1 | conda list -e > requirements.txt |
pip批量安装requirements.txt文件中包含的组件依赖
1 | conda install --yes --file requirements.txt |