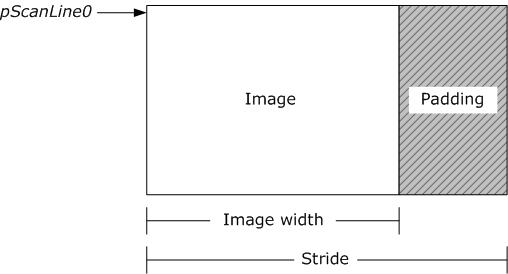
webrtc的base的 thread,是我见过的封装最帅的c++线程库,根据比qt的还好用,发个例子给你
1 | using namespace webrtc; |
有ios的gdc,android的handler异曲同工
因为编写复杂稳定的多线程C++项目实在太难,所以一个好的跨平台C++基础库是我最求的目标,目前比较欣赏的项目有:
Boost:大而全,缺少一些可以直接上手的东西如线程消息队列,智能指针并非线程安全。 QT core:非常好 C++11:也需要线程消息队列,线程安全智能指针。 chromium的base库:太大了 当我看到webrtc的base时,非常惊讶的发现它正是我想要的,特点:
小:只有几M 纯:基于c++标准库和各操作系统sdk 跨平台 对智能指针、线程、socket封装非常好。 不断更新(需要一直跟踪官方代码) 移植出来单独使用,方案有三:
把源码拷贝出来用通用的编译工具(makefile,cmake,qmake)管理。(makefile较复杂,cmake简单,qmake最简单) 把源码拷贝出来用基于自带的gn管理 在webrtc项目里面编译和合并需要的静态库和pdb
因为google官方说了:引用计数+引用计数的智能化(scoped_ref_ptr)+弱引用就可以解决问题。 shared_ptr不是线程安全的,因为shared_ptr有两个成员:引用计数,和源对象指针。没办法对两个成员同时实现原子操作。 但unique_ptr是个好东西
智能指针的使用:
- 不用再使用delete。
- 尽量使用unique_ptr。
- 多个线程读写同一个 shared_ptr 对象,那么需要加锁。
- shared_ptr 和weak_ptr配合解决循环引用的问题。
weak_ptr必须,oc,swift的ViewControler和控件都是weak关系
内存管理模型的三种级别: 1 手动内存管理(c/c++的malloc与free,new与delete):容易出错。 2 自动内存管理(oc的arc,c++的智能指针,scoped_ptr):存在循环引用问题,通过程序员自己管理强弱引用关系解决。 3 垃圾回收机制(如java,python):后台GC降低了程序效率,好的程序员仍然好考虑java的强引用[表情]引用/软引用/
3 线程模型 1 生产者消费模型(mutex,condition):最最常用的模型。 2 线程池模型:解决大量请求分配太多线程的问题。比如一个android和ios的app,http请求会很多很多。 3 (着重强调)串行模型:ios有GCD(Grand Central Dispatch,global queue是线程池),android有looper, win32有PostMessage,boost有strand 读写锁:特别只有写才会不安全的情况。 再结合其他的手段会让程序简洁优美易读:java的handler,oc的delegate和block、swift的闭包,mvc模式 ,c++的function/bind/lambda,python和javascript的function
而串行模型就成了解决这类多线程问题的首选,就是线程消息模型。 在android 系统里面,无数这样的例子。
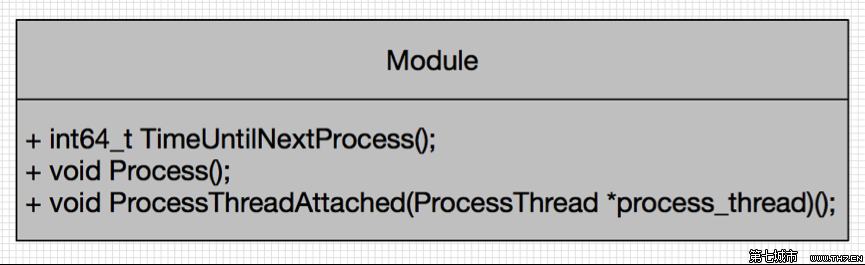
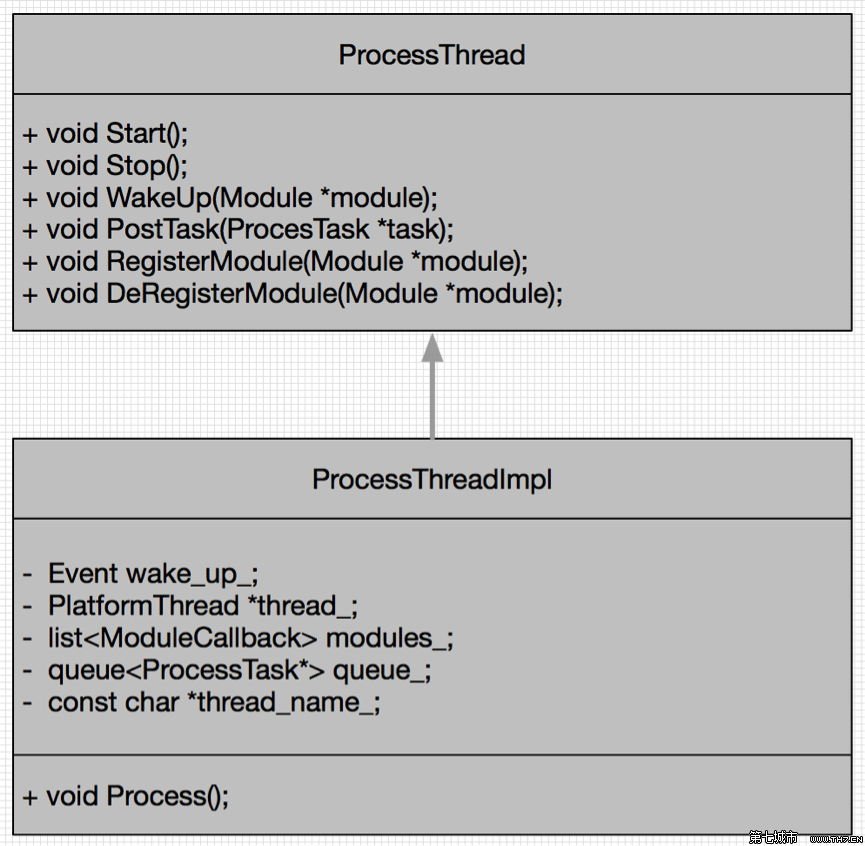
模块处理线程
Call构造方法中创建module_process_thread与pacer_thread两个ProcessThread.接着为module_process_thread注册CallStats, ReceiveSideCongestionController, SendSideCongestionController模块,为pacer_thread注册PacedSender, RemoteBitrateEstimator模块.
Call::CreateVideoSendStream创建VideoSendStream时,将module_process_thread做构造参数传入,调用RegisterProcessThread方法,注册所有的rtc_rtcp模块到module_process_thread线程.同样的为VideoReceiveStream中设置.
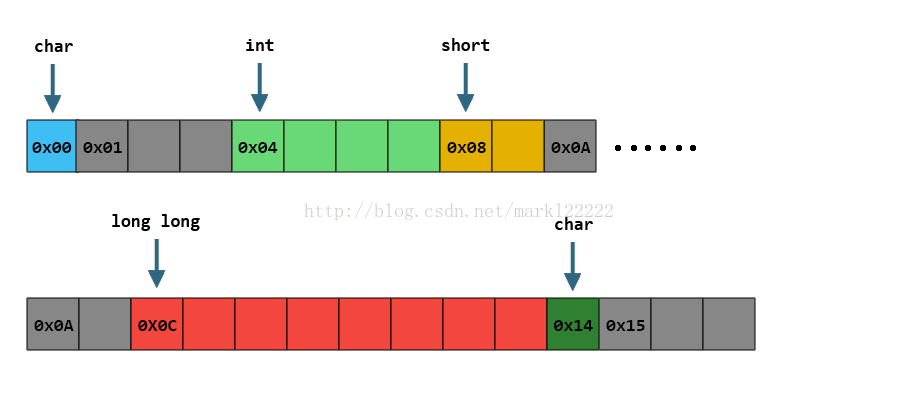
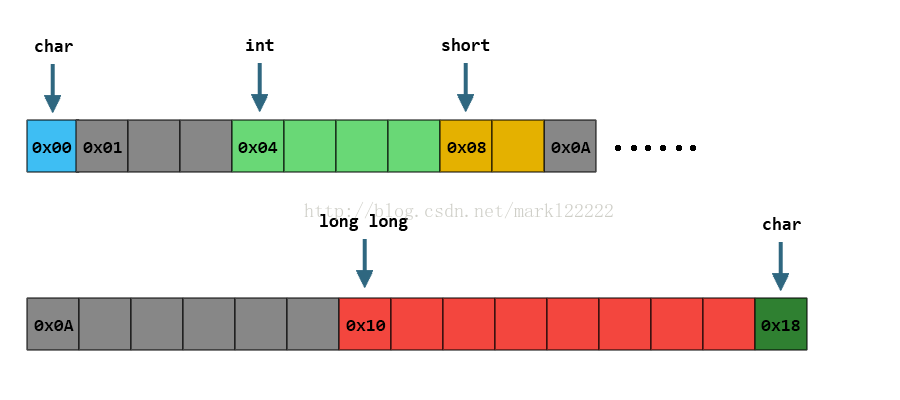 我们可以看到,char和int之间;short和long long之间,为了保证成员各自的对齐属性,分别插入了一些Padding。
因此整个结构体会被填充得看起来像这样:
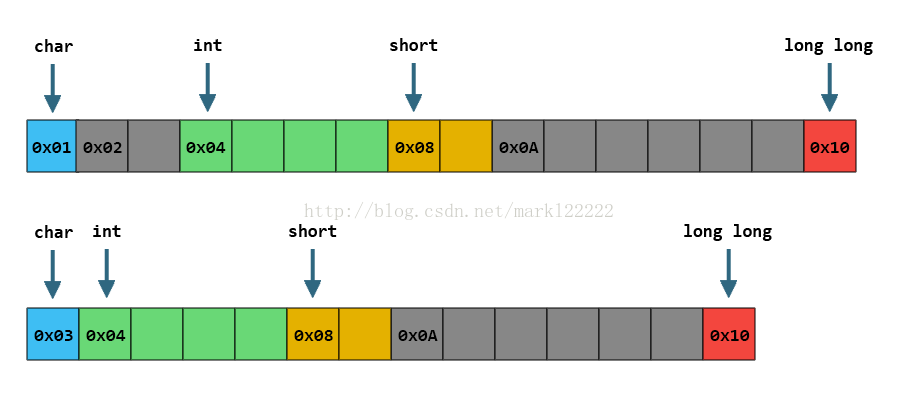
我们可以看到,char和int之间;short和long long之间,为了保证成员各自的对齐属性,分别插入了一些Padding。
因此整个结构体会被填充得看起来像这样: