前言
有关APK更新的技术比较多,例如:增量更新、插件式开发、热修复、RN、静默安装。 下面简单介绍一下:
| 更新方式 | 签名 |
|---|---|
| 增量更新 | 旧版本Apk(v1.0)和新(v2.0)、旧版本Apk(v1.0)生成的差分包(apk.patch 质量小)合并成为新版本Apk(v2.0)安装。 |
| 插件式开发 | 给宿主APK提供插件,扩展(需要的时候再下载),可以动态地替换。主要技术是动态代理的知识。 |
| 热修复 | 通过NDK底层去修复,也是C/C++的技术。 |
| RN | 通过JS脚本去修复APK。 |
| 静默安装 | 需要root权限,适配不同手机ROM很麻烦。 |
插件化、热修复(思想)的发展历程
- 2012年7月,AndroidDynamicLoader,大众点评,陶毅敏:思想是通过Fragment以及schema的方式实现的,这是一种可行的技术方案,但是还有限制太多,这意味这你的activity必须通过Fragment去实现,这在activity跳转和灵活性上有一定的不便,在实际的使用中会有一些很奇怪的bug不好解决,总之,这还是一种不是特别完备的动态加载技术。
- 2013年,23Code,自定义控件的动态下载:主要利用 Java ClassLoader 的原理,可动态加载的内容包括 apk、dex、jar等。
- 2014年初,Altas,阿里伯奎的技术分享:提出了插件化的思想以及一些思考的问题,相关资料比较少。
- 2014年底,Dynamic-load-apk,任玉刚:动态加载APK,通过Activity代理的方式给插件Activity添加生命周期。
- 2015年4月,OpenAltas/ACCD:Altas的开源项目,一款强大的Android非代理动态部署框架,目前已经处于稳定状态。
- 2015年8月,DroidPlugin,360的张勇:DroidPlugin 是360手机助手在 Android 系统上实现了一种新的插件机制:通过Hook思想来实现,它可以在无需安装、修改的情况下运行APK文件,此机制对改进大型APP的架构,实现多团队协作开发具有一定的好处。
- 2015年9月,AndFix,阿里:通过NDK的Hook来实现热修复。
- 2015年11月,Nuwa,大众点评:通过dex分包方案实现热修复。
- 2015年底,Small,林光亮:打通了宿主与插件之间的资源与代码共享。
- 2016年4月,ZeusPlugin,掌阅:ZeusPlugin最大特点是:简单易懂,核心类只有6个,类总数只有13个。
1.增量更新
增量更新就是原有app的基础上只更新发生变化的地方,其余保持原样。 与原来每次更新都要下载完整apk包的做法相比,这样做的好处显而易见:每次变化的地方总是比较少,因此更新包的体积就会小很多。
1.1增量更新的流程
- APP检测最新版本:把当前版本告诉服务端,服务端进行判断。 如果有新版本,服务端需要对当前版本的APK与最新版本的APK进行一次差分,产生patch差分文件。(或者新版本的APK上传到服务端的时候就已经差分好了)
- APP在后台下载差分文件,进行文件的MD5校验,在本地进行合并(跟本地的data目录下面的APK文件合并),合并出最新的APK之后,提示用户安装。
- 增量更新的最终目的:省流量地更新宿主APK。
差分的处理比较麻烦的地方就是要针对不同的应用市场渠道和众多不同版本进行差分。 注意:新版本有可能比旧版本小,差分只是把变化的部分记录下来。
1.2服务器端行为(后台工程师操作)
1.2.1下载拆分和合并要用的第三方库(bsdiff、bzip2)
我们使用到的第三方库是:Binary diff,简称bsdiff,这个库专门用来实现文件的差分和合并的,它的官网如下:http://www.daemonology.net/bsdiff/
1.2.2Java代码调用:
创建Web项目,用来做APP的服务端。创建工具类专门用于产生差分包:
1 | public class BsDiff { |
其中JNI的实现如下(该实现写在bsdiff.cpp中):
1 | JNIEXPORT void JNICALL Java_com_haocai_bsdiff_BsDiff_diff |
通过研究bsdiff的源码,我们发现bsdiff.cpp里面的main函数就是入口函数,避免歧义把函数名main改为bsdiff_main,然后通过JNI去调用。根据bsdiff.cpp中bsdiff_main函数方法中有以下关键语句
1 | if (argc != 4) errx(1, "usage: %s oldfile newfile patchfile\n", argv[0]); |
根据提示需要传入4个参数:
1 | argv[0] = "bsdiff";//这个参数没用 |
然后我们准备两个APK文件,不同版本的,最好Java代码、资源都不一样。
写一个Java测试类生成差分包:
1 | package com.haocai.bsdiff; |
1 | package com.haocai.bsdiff; |
注意:
- test_new.apk、test_old.apk 要先放在目标目录
- bsdiff.cpp中生成差分包的程序方法是异步的,所以生成完整的apk.patch可能要等一下。apk.patch体积大小停止增长,表示生成结束。
1.2.3简单搭建后台JavaWeb供Android前端下载apk.patch差分包
1.3Android客户端行为
1.3.1编译合并要用的第三方库(bsdiff、bzip2)
对应的Java代码如下:
1 | package com.haocai.app.update; |
在Android端,我们需要把bzip2以及bsdiff的文件拷贝到jni目录里面,同样的,我们只需要编译一个bspatch.c源文件即可。
1 | //合并 |
代码v1.0差分包合并核心代码如下:
1 | package com.haocai.app.update; |
注意:这里7.0可能会有问题,把路径暴露给别的app,需要FileProvider去实现(不难,这个留给大家去做吧)。
2.插件化
插件化框架的一些对比,下面引用 https://github.com/wequick/Small/blob/master/Android/COMPARISION.md
| 特性 | DynamicLoadApk | DynamicAPK | Small | DroidPlugin | VirtualAPK | RePlugin |
|---|---|---|---|---|---|---|
| 支持四大组件 | 只支持Activity | 只支持Activity | 只支持Activity | 全支持 | 全支持 | 全支持 |
| 组件无需在宿主manifest中预注册 | √ | × | √ | √ | √ | √ |
| 插件可以依赖宿主 | √ | √ | √ | × | √ | √ |
| 支持PendingIntent | × | × | × | √ | √ | √ |
| Android特性支持 | 大部分 | 大部分 | 大部分 | 几乎全部 | 几乎全部 | 几乎全部 |
| 兼容性适配 | 一般 | 一般 | 中等 | 高 | 高 | 高 |
| 插件构建 | 无 | 部署aapt | Gradle插件 | 无 | Gradle插件 | Gradle插件 |
| 源码 | https://github.com/singwhatiwanna/dynamic-load-apk |
https://github.com/CtripMobile/DynamicAPK |
https://github.com/wequick/Small | https://github.com/DroidPluginTeam/DroidPlugin |
https://github.com/didi/VirtualAPK |
https://github.com/Qihoo360/RePlugin |
| 开发者 | singwhatiwanna | CtripMobile | Lody | 滴滴 | 360 |
2.1DynamicLoadApk
基于静态代理的实现
2.2VirtualAPK
2.2.1特性
| Feature | Detail |
|---|---|
| Supported components | Activity, Service, Receiver and Provider |
| Manually register components in AndroidManifest.xml | No need |
| Access host app classes and resources | Supported |
| PendingIntent | Supported |
| Supported Android features | Almost all features |
| Compatibility | Almost all devices |
| Building system | Gradle plugin |
| Supported Android versions | API Level 15+ |
| ##### 2.2.2架构 | |
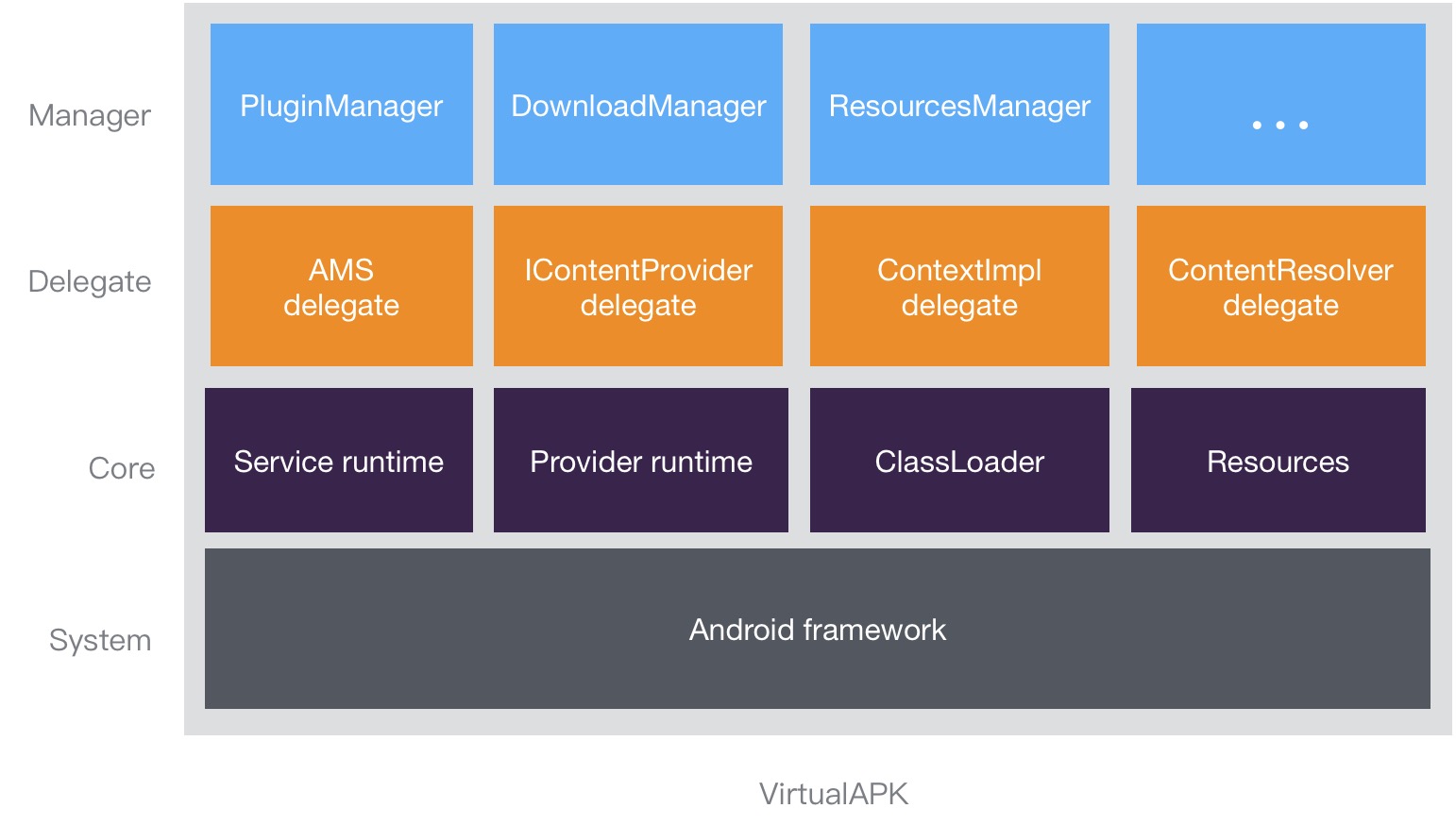 |
2.2.3原理
2.2.3.1基本原理
- 合并宿主和插件的ClassLoader 需要注意的是,插件中的类不可以和宿主重复
- 合并插件和宿主的资源 重设插件资源的packageId,将插件资源和宿主资源合并
- 去除插件包对宿主的引用 构建时通过Gradle插件去除插件对宿主的代码以及资源的引用
2.2.3.2四大组件的实现原理
- Activity 采用宿主manifest中占坑的方式来绕过系统校验,然后再加载真正的activity;
- Service 动态代理AMS,拦截service相关的请求,将其中转给Service Runtime去处理,Service Runtime会接管系统的所有操作;
- Receiver 将插件中静态注册的receiver重新注册一遍;
- ContentProvider 动态代理IContentProvider,拦截provider相关的请求,将其中转给Provider Runtime去处理,Provider Runtime会接管系统的所有操作。
2.3RePlugin
2.3.1特性
| 特性 | 描述 |
|---|---|
| 组件 | 四大组件(含静态Receiver) |
| 升级无需改主程序Manifest | 完美支持 |
| Android特性 | 支持近乎所有(包括SO库等) |
| TaskAffinity & 多进程 | 支持(坑位方案) |
| 插件类型 | 支持自带插件(自识别)、外置插件 |
| 插件间耦合 | 支持Binder、Class Loader、资源等 |
| 进程间通讯 | 支持同步、异步、Binder、广播等 |
| 自定义Theme & AppComat | 支持 |
| DataBinding | 支持 |
| 安全校验 | 支持 |
| 资源方案 | 独立资源 + Context传递(相对稳定) |
| Android 版本 | API Level 9+ (2.3及以上) |
2.3.2架构
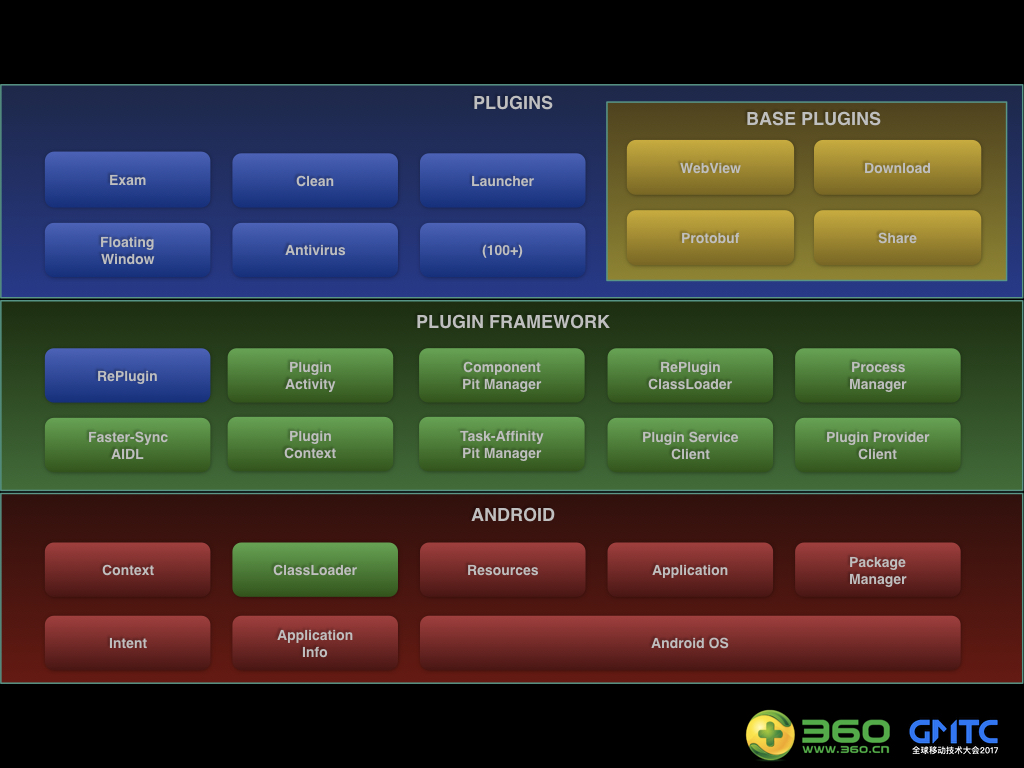
模块化,组件化,插件化
在技术开发领域,模块化是指分拆代码,即当我们的代码特别臃肿的时候,用模块化将代码分而治之、解耦分层。具体到 android 领域,模块化的具体实施方法分为插件化和组件化。
一套完整的插件化或组件化都必须能够实现单独调试、集成编译、数据传输、UI 跳转、生命周期和代码边界这六大功能。
解耦思想: 控制反转是一种思想,依赖注入是一种设计模式,IoC框架使用依赖注入作为控制反转的方式
模块化粒度更小,更侧重于重用,而组件化粒度稍大于模块,更侧重于业务解耦。 组件化的核心是角色的转换。 在打包时, 是library; 在调试时, 是application。 组件化开发是纵向分层,模块化开发是横向分块。
组件化想要解决的问题:
- 实际业务变化非常快,但是工程之前的业务模块耦合度太高,牵一发而动全身.
- 对工程所做的任何修改都必须要编译整个工程
- 功能测试和系统测试每次都要进行.
- 团队协同开发存在较多的冲突.不得不花费更多的时间去沟通和协调,并且在开发过程中,任何一位成员没办法专注于自己的功能点,影响开发效率.
- 不能灵活的对工程进行配置和组装.比如今天产品经理说加上这个功能,明天又说去掉,后天在加上.
组件开发比较常见的问题是业务组件的相互引用,为此我们可以通过路由/总线的方式去处理,挂载到组件总线上的业务组件,都可以实现双向通信.而通信协议和HTTP通信协议类似,即基于URL的方式进行.
相对于组件化开发主要要解决的问题:
- 宿主和插件分开编译
- 并发开发
- 动态更新插件
- 按需下载模块
- 方法数或变量数爆棚
插件化组件化的区别:
- 组件化的单位是组件(module);插件化的单位是apk(一个完整的应用)。
- 组件化实现的是解耦与加快编译, 隔离不需要关注的部分;插件化实现的也是解耦与加快编译,同时实现热插拔也就是热更新。
- 组件化的灵活性在于按加载时机切换,分离出独立的业务组件,比如微信的朋友圈;插件化的灵活性在于是加载apk, 完全可以动态下载,动态更新,比组件化更灵活。
- 组件化能做的只是, 朋友圈已经有了,我想单独调试,维护,和别人不耦合,但是和整个项目还是有关联的;插件化可以说朋友圈就是一个app, 我需要整合了,把它整合进微信这个大的app里面
其实从框架名称就可以看出: 组 和 插。 组本来就是一个系统,你把微信分为朋友圈,聊天, 通讯录按意义上划为独立模块,但并不是真正意义上的独立模块。 插本来就是不同的apk, 你把微信的朋友圈,聊天,通讯录单独做一个完全独立的app, 需要微信的时候插在一起,就是一个大型的app了。 插件化的加载是动态的,这点很重要,也是灵活的根源。
所谓架构,无非两个方面: 分层和通信方式。 其实广义的架构也可以说是这两个方面:子模块(子系统)划分和通信。
子模块划分 除了大家公认的common部分, 业务模块的划分尤为重要,相比于狭义上的架构,广义上的子系统的划分的关注点,很考验技术经验以及对业务的理解。
通信方式 模块化的通信方式,无非是相互引入;我抽取了common, 其他模块使用自然要引入这个module 组件化的通信方式,按理说可以划分为多种,主流的是隐式和路由。隐式的存在使解耦与灵活大大降低,因此路由是主流 插件化的通信方式,不同插件本身就是不同的进程了。因此通信方式偏向于Binder机制类似的进程间通信 移动端目前的架构,差异化在于通信机制。通过以上说明,通信机制主要分为3种:
- 对象持有
- 接口持有
- 路由 通信方式中,对象持有是比较原始的,解耦率最低,建议放弃; 接口持有是个不错的选择,极大程度上实现解耦的诉求,但是解耦不彻底,相互持有交互方的接口。 路由机制也是个不错的选择,可以实现完全解耦,就像组件化一样。但是路由机制的设计是个技术难点,怎么设计效率最高?更健壮?代码可查阅性更好?这些都是值得思考的问题。对于路由机制的优化,阿里的ARouter(用于组件通信)中,采用了分组的模式,我们可以采用;其次可以根据AnnotationProcessor的处理,为每一个注册接收器的组件实现一个SupportActions来确保消息只发送给注册了指定类型的模块,也是个不错的选择。
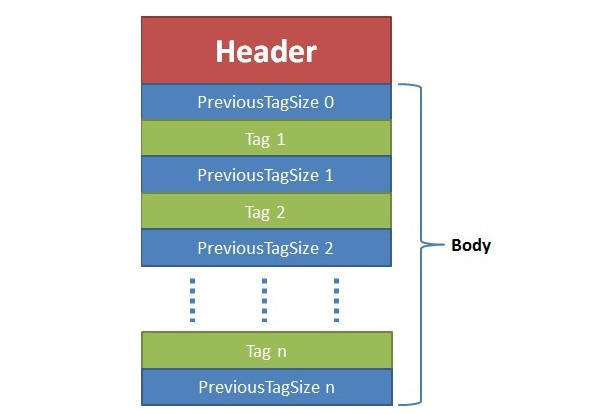
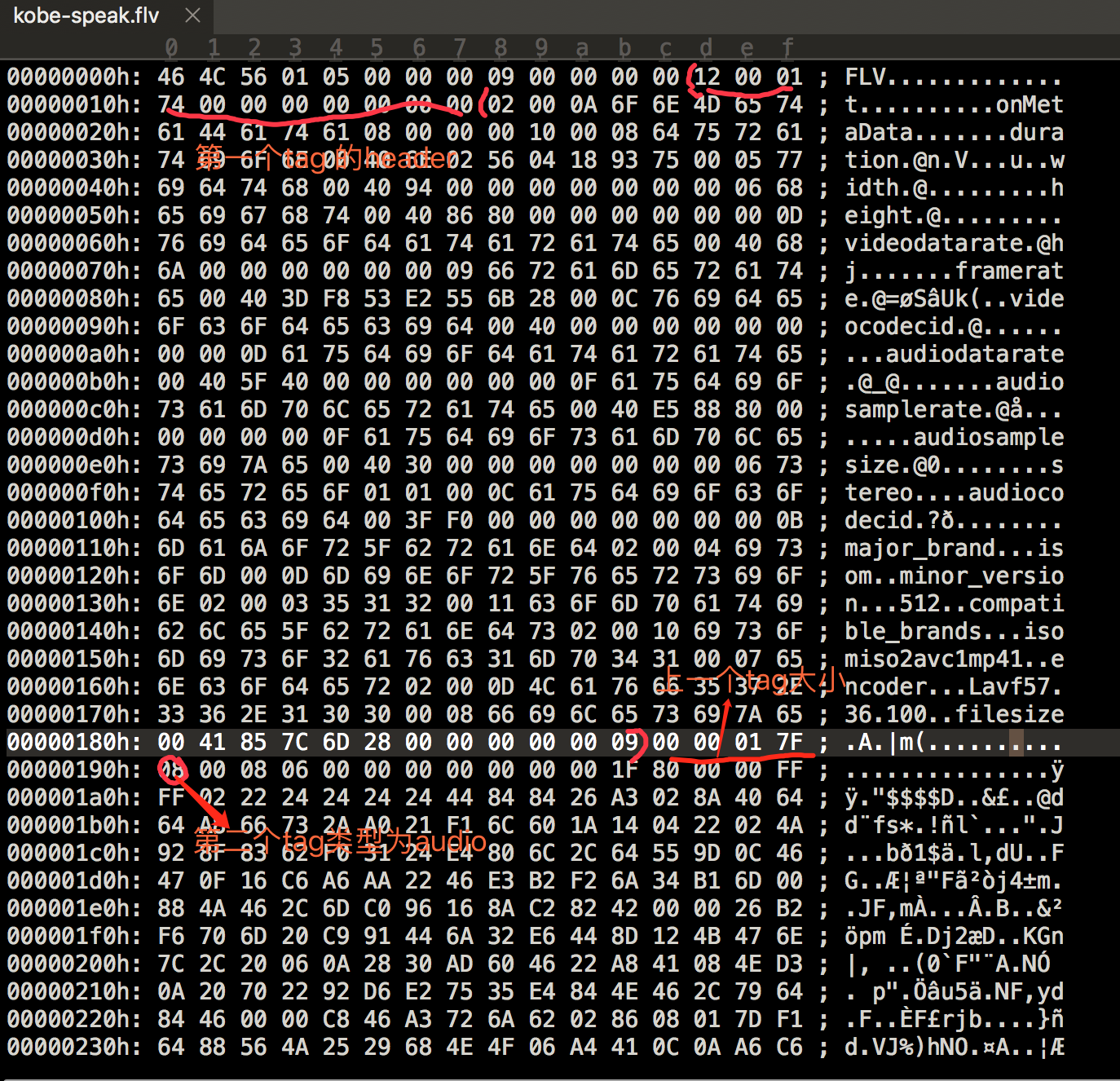
 上图为第一个AMF包
上图为第一个AMF包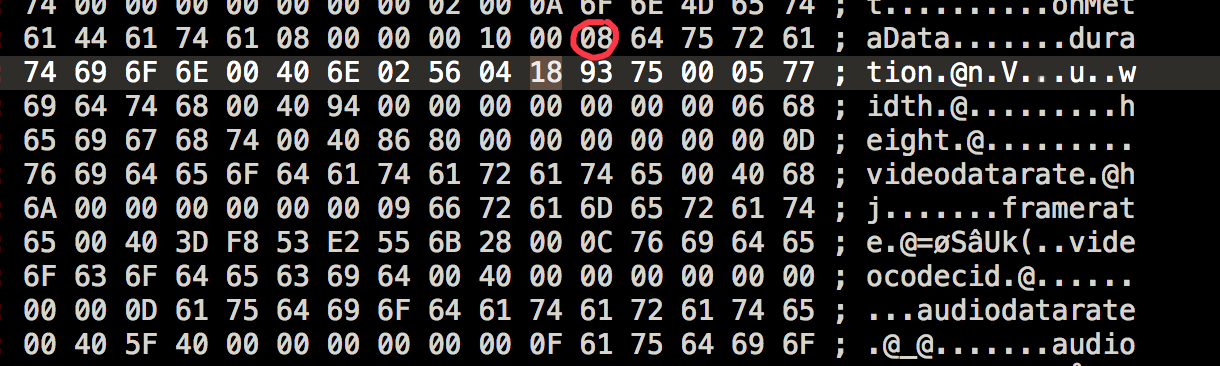 上图为第二个AMF
上图为第二个AMF
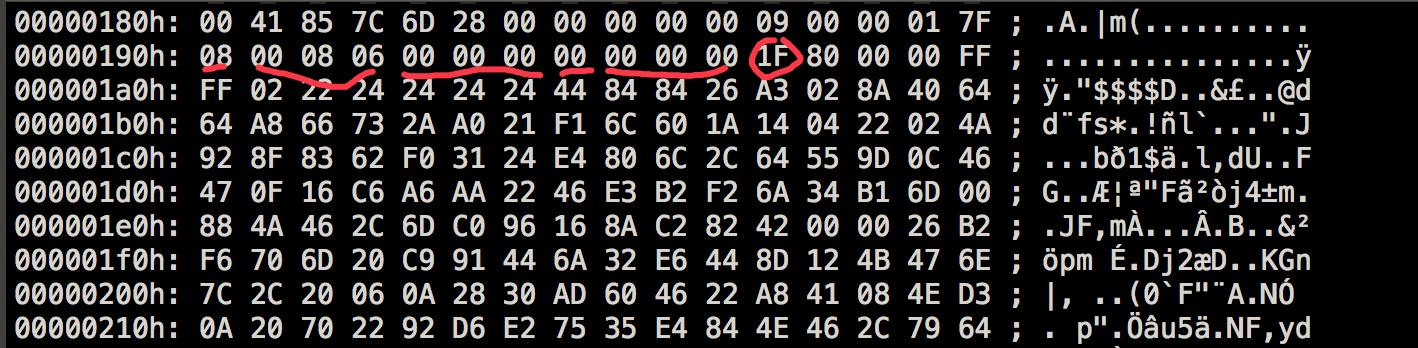
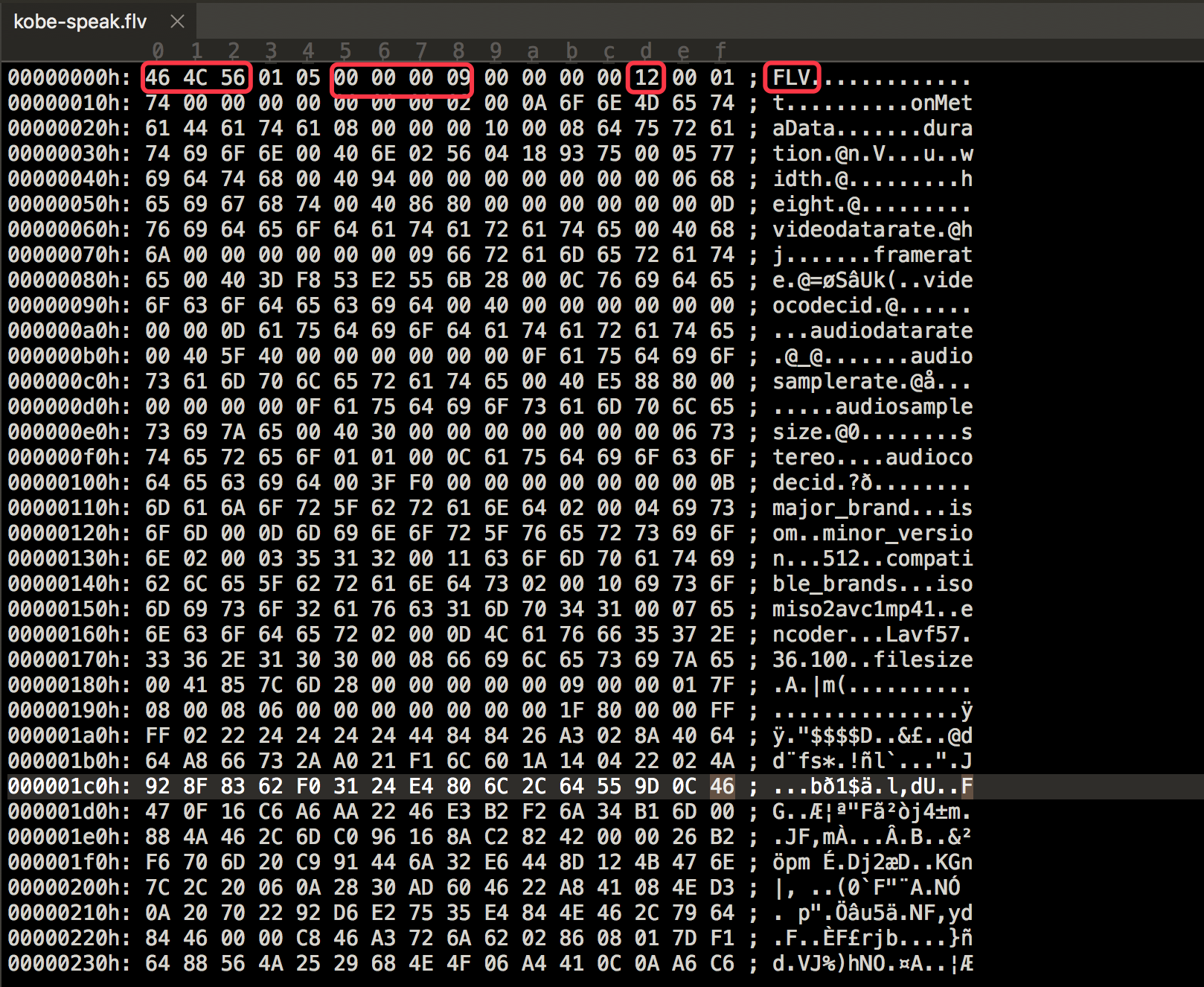
 视频中第二个tag为音频tag
视频中第二个tag为音频tag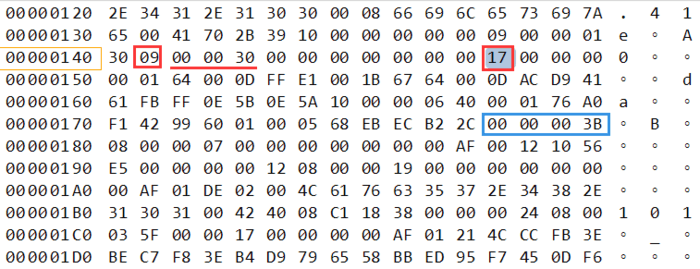
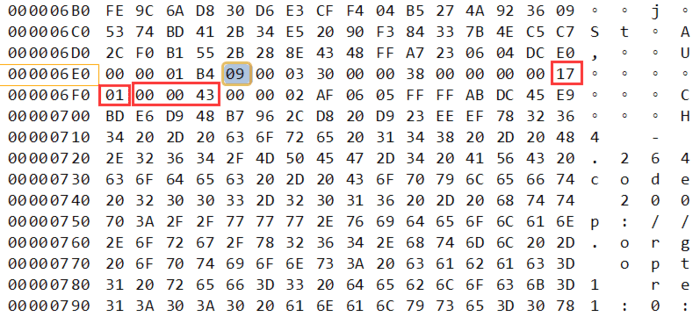
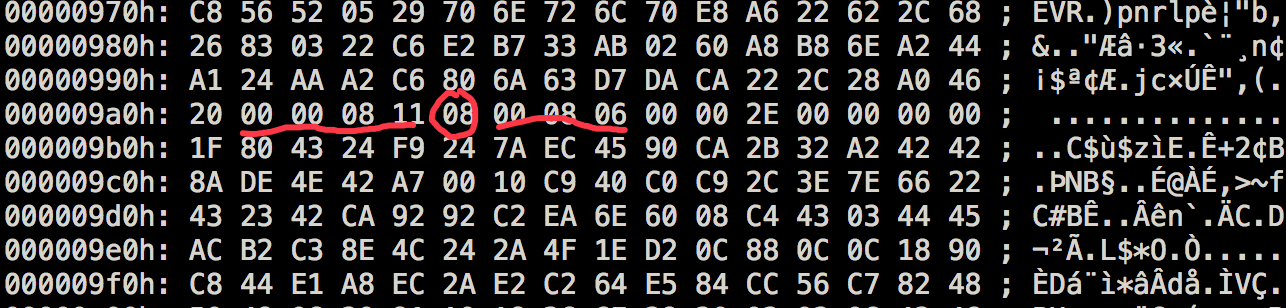
 这是第二个video tag其实和之前图一样,只是我圈出来关键信息。先看下格式
frametype=0x17=00010111
AVCPacketType =1
Composition Time=0x000043
后面就是NALU DATA
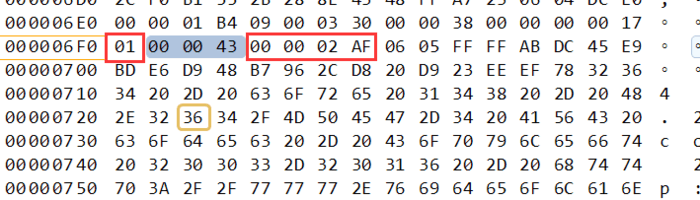
这是第二个video tag其实和之前图一样,只是我圈出来关键信息。先看下格式
frametype=0x17=00010111
AVCPacketType =1
Composition Time=0x000043
后面就是NALU DATA