信息论的观点来看,描述信源的数据是信息和数据冗余之和,即:数据=信息+数据冗余。音频信号在时域和频域上具有相关性,也即存在数据冗余。将音频作为一个信源,音频编码的实质是减少音频中的冗余。 自然界中的声音非常复杂,波形极其复杂,通常我们采用的是脉冲代码调制编码,即PCM编码。PCM通过抽样、量化、编码三个步骤将连续变化的模拟信号转换为数字编码。
内容介绍
声音三要素
声音的特性可由三个要素来描述,即响度、音调和音色。
- 响度:人耳对声音强弱的主观感觉称为响度。响度和声波振动的幅度有关。一般说来,声波振动幅度越大则响度也越大。当我们用较大的力量敲鼓时,鼓膜振动的幅度大,发出的声音响;轻轻敲鼓时,鼓膜振动的幅度小,发出的声音弱。 音叉振动时发出的声波为单音,即只有一个频率成分。若设法将音叉的振动规律记录下来,可发现其振动波形为一正弦波。当用不同力量敲击某个音叉时,音叉发出的声波幅度不同,这意味着声音的响度不同。给出了两个声音波形,其幅度一大一小,幅度大的波形其声音响度大,幅度小的波形其声音响度小。另外,人们对响度的感觉还和声波的频率有关,同样强度的声波,如果其频率不同,人耳感觉到的响度也不同。
- 音调:人耳对声音高低的感觉称为音调。音调主要与声波的频率有关。声波的频率高,则音调也高。当我们分别敲击一个小鼓和一个大鼓时,会感觉它们所发出的声音不同。小鼓被敲击后振动频率快,发出的声音比较清脆,即音调较高;而大鼓被敲击后振动频率较慢,发出的声音比较低沉,即音调较低。如果分别敲击一个小音叉和一个大音叉时,同样会感觉到小音叉所发声音的音调较高,大音叉所发声音音调较低。如果设法把大、小音叉所发出的声波记录下来,可发现小音叉在单位时间内振动的次数多,即频率高,大音叉在单位时间内振动的次数少,即频率低。给出了两个频率不同的声音波形,从声音可听出,频率高的声音波形听起来音调较高,而频率低的声音波形听起来则音调较低。
- 音色:音色是人们区别具有同样响度、同样音调的两个声音之所以不同的特性,或者说是人耳对各种频率、各种强度的声波的综合反应。音色与声波的振动波形有关,或者说与声音的频谱结构有关。前面说过,音叉可产生一个单一频率的声波,其波形为正弦波。但实际上人们在自然界中听到的绝大部分声音都具有非常复杂的波形,这些波形由基波和多种谐波构成。谐波的多少和强弱构成了不同的音色。各种发声物体在发出同一音调声音时,其基波成分相同。但由于谐波的多少不同,并且各次谐波的幅度各异,因而产生了不同的音色。 例如当我们听胡琴和扬琴等乐器同奏一个曲子时,虽然它们的音调相同,但我们却能把不同乐器的声音区别开来。这是因为,各种乐器的发音材料和结构不同,它们发出同一个音调的声音时,虽然基波相同,但谐波构成不同,因此产生的波形不同,从而造成音色不同。给出了小提琴和钢琴的波形和声音,这两个声音的响度和音调都是相同的,但听起来却不一样,这就是因为这两个声音的音色不同(波形不同)。
音调是指声音的高低,它是由声源振动的频率决定的.响度是指声音的大小,它是由声源振动的振幅决定的且与距离有关。比如我们看电视时,调节音量开关,可以控制声音的大小,而不能改变音调的高低.在日常生活用的语言中,往往用“高低”来表示声音的大小,比如“高声喧哗”中的“高”,不是指音调高低,而是指声音“大小”.在学习中不注意声音大小和高低的区别,会造成音调和响度两个不同的概念模糊不清,这在学习中应该引起特别注意。
采样率和采样大小
声音其实是一种能量波,因此也有频率和振幅的特征,频率对应于时间轴线,振幅对应于电平轴线。波是无限光滑的,弦线可以看成由无数点组成,由于存储空间是相对有限的,数字编码过程中,必须对弦线的点进行采样。采样的过程就是抽取某点的频率值,很显然,在一秒中内抽取的点越多,获取得频率信息更丰富,为了复原波形,一次振动中,必须有2个点的采样,人耳能够感觉到的最高频率为20kHz,因此要满足人耳的听觉要求,则需要至少每秒进行40k次采样,用40kHz表达,这个40kHz就是采样率。我们常见的CD,采样率为44.1kHz。光有频率信息是不够的,我们还必须获得该频率的能量值并量化,用于表示信号强度。量化电平数为2的整数次幂,我们常见的CD位16bit的采样大小,即2的16次方。采样大小相对采样率更难理解,因为要显得抽象点,举个简单例子:假设对一个波进行8次采样,采样点分别对应的能量值分别为A1-A8,但我们只使用2bit的采样大小,结果我们只能保留A1-A8中4个点的值而舍弃另外4个。如果我们进行3bit的采样大小,则刚好记录下8个点的所有信息。采样率和采样大小的值越大,记录的波形更接近原始信号。
有损和无损
根据采样率和采样大小可以得知,相对自然界的信号,音频编码最多只能做到无限接近,至少目前的技术只能这样了,相对自然界的信号,任何数字音频编码方案都是有损的,因为无法完全还原。在计算机应用中,能够达到最高保真水平的就是PCM编码,被广泛用于素材保存及音乐欣赏,CD、DVD以及我们常见的WAV文件中均有应用。因此,PCM约定俗成了无损编码,因为PCM代表了数字音频中最佳的保真水准,并不意味着PCM就能够确保信号绝对保真,PCM也只能做到最大程度的无限接近。我们而习惯性的把MP3列入有损音频编码范畴,是相对PCM编码的。强调编码的相对性的有损和无损,是为了告诉大家,要做到真正的无损是困难的,就像用数字去表达圆周率,不管精度多高,也只是无限接近,而不是真正等于圆周率的值。
使用音频压缩技术的原因
要算一个PCM音频流的码率是一件很轻松的事情,采样率值×采样大小值×声道数 bps。一个采样率为44.1KHz,采样大小为16bit,双声道的PCM编码的WAV文件,它的数据速率则为 44.1K×16×2 =1411.2 Kbps。我们常说128K的MP3,对应的WAV的参数,就是这个1411.2 Kbps,这个参数也被称为数据带宽,它和ADSL中的带宽是一个概念。将码率除以8,就可以得到这个WAV的数据速率,即176.4KB/s。这表示存储一秒钟采样率为44.1KHz,采样大小为16bit,双声道的PCM编码的音频信号,需要176.4KB的空间,1分钟则约为10.34M,这对大部分用户是不可接受的,尤其是喜欢在电脑上听音乐的朋友,要降低磁盘占用,只有2种方法,降低采样指标或者压缩。降低指标是不可取的,因此专家们研发了各种压缩方案。由于用途和针对的目标市场不一样,各种音频压缩编码所达到的音质和压缩比都不一样,在后面的文章中我们都会一一提到。有一点是可以肯定的,他们都压缩过。
频率与采样率的关系
采样率表示了每秒对原始信号采样的次数,我们常见到的音频文件采样率多为44.1KHz,这意味着什么呢?假设我们有2段正弦波信号,分别为20Hz和20KHz,长度均为一秒钟,以对应我们能听到的最低频和最高频,分别对这两段信号进行40KHz的采样,我们可以得到一个什么样的结果呢?结果是:20Hz的信号每次振动被采样了40K/20=2000次,而20K的信号每次振动只有2次采样。显然,在相同的采样率下,记录低频的信息远比高频的详细。这也是为什么有些音响发烧友指责CD有数码声不够真实的原因,CD的44.1KHz采样也无法保证高频信号被较好记录。要较好的记录高频信号,看来需要更高的采样率,于是有些朋友在捕捉CD音轨的时候使用48KHz的采样率,这是不可取的!这其实对音质没有任何好处,对抓轨软件来说,保持和CD提供的44.1KHz一样的采样率才是最佳音质的保证之一,而不是去提高它。较高的采样率只有相对模拟信号的时候才有用,如果被采样的信号是数字的,请不要去尝试提高采样率。
亨利·奈奎斯特(Harry Nyquist)采样定理:当对连续变化的信号波形进行采样时,若采样率fs高于该信号所含最高频率的两倍,那么可以由采样值通过插补技术正确的回复原信号中的波形,否则将会引起频谱混叠(Aliasing),产生混叠噪音(Aliasing Noise),而重叠的部分是不能恢复的.(同样适用于模拟视频信号的采样) 人声语音的特点。人类的听力感知范围是从20Hz到20kHz。这个频宽范围被划分成四个频宽类别:窄带、宽带、超宽带和全带。
音轨和声道的区别?
- 音轨:过去,当歌手在录音棚里录音的情况跟现在大不一样 就是让歌手和乐队一起录音 歌手一边唱,乐队一边伴奏 然后录音机把这些声音一起录下来。 大多数读者都认为录音就是这样录 而且过去也的确这样录的 不过这样录音有一个很不方便的地方 那就是,如果歌手唱错了,录音师要歌手从新开始唱 那么乐队也要重新开始伴奏 如果歌手唱错一两次还没大关系 如果歌手唱错三、四次甚至是更多次数 那么乐队就要跟着重新伴奏四、五次或更多 而且这样的情况并不少见 这样乐队就会产生不满的情绪 还会产生其他一┎环奖? 后来就采用了一项新技术,可以避免这样的不便 那就是让乐队单独演奏,并用录音设备录下来,只是录在单独一条音轨上 然后让歌手带上耳机,听着乐队的伴奏录音演唱, 并录下来,录在另一条和伴奏音轨平行的音轨上 如果歌手唱错了,需要重新唱,只要把伴奏录音重新放就可以了 这种技术就是双音轨技术,这种技术能够把多种声音混合的录在一起,实现各种美妙的音效 其实我们唱的卡拉OK就是采用了音轨技术 其实以上说的是双音轨技术,还有多音轨技术,可以把三、四种声音或者更多的声音分别录制成单独的音轨然后一起播放出来
- 声道数:声卡所支持的声道数是衡量声卡档次的重要指标之一,从单声道到最新的环绕立体声,下面一一详细介绍:
- 单声道 单声道是比较原始的声音复制形式,早期的声卡采用的比较普遍。当通过两个扬声器回放单声道信息的时候,我们可以明显感觉到声音是从两个音箱中间传递到我们耳朵里的。这种缺乏位置感的录制方式用现在的眼光看自然是很落后的,但在声卡刚刚起步时,已经是非常先进的技术了。
- 立体声 单声道缺乏对声音的位置定位,而立体声技术则彻底改变了这一状况。声音在录制过程中被分配到两个独立的声道,从而达到了很好的声音定位效果。这种技术在音乐欣赏中显得尤为有用,听众可以清晰地分辨出各种乐器来自的方向,从而使音乐更富想象力,更加接近于临场感受。立体声技术广泛运用于自Sound Blaster Pro以后的大量声卡,成为了影响深远的一个音频标准。时至今日,立体声依然是许多产品遵循的技术标准。
- 准立体声 准立体声声卡的基本概念就是:在录制声音的时候采用单声道,而放音有时是立体声,有时是单声道。采用这种技术的声卡也曾在市面上流行过一段时间,但现在已经销声匿迹了。
- 四声道环绕 人们的欲望是无止境的,立体声虽然满足了人们对左右声道位置感体验的要求,但是随着技术的进一步发展,大家逐渐发现双声道已经越来越不能满足我们的需求。由于PCI声卡的出现带来了许多新的技术,其中发展最为神速的当数三维音效。三维音效的主旨是为人们带来一个虚拟的声音环境,通过特殊的HRTF技术营造一个趋于真实的声场,从而获得更好的游戏听觉效果和声场定位。而要达到好的效果,仅仅依靠两个音箱是远远不够的,所以立体声技术在三维音效面前就显得捉襟见肘了,但四声道环绕音频技术则很好的解决了这一问题。 四声道环绕规定了4个发音点:前左、前右,后左、后右,听众则被包围在这中间。同时还建议增加一个低音音箱,以加强对低频信号的回放处理(这也就是如今4.1声道音箱系统广泛流行的原因)。就整体效果而言,四声道系统可以为听众带来来自多个不同方向的声音环绕,可以获得身临各种不同环境的听觉感受,给用户以全新的体验。如今四声道技术已经广泛融入于各类中高档声卡的设计中,成为未来发展的主流趋势。
- 5.1声道
- 1声道已广泛运用于各类传统影院和家庭影院中,一些比较知名的声音录制压缩格式,譬如杜比AC-3(Dolby Digital)、DTS等都是以5.1声音系统为技术蓝本的,其中“.1”声道,则是一个专门设计的超低音声道,这一声道可以产生频响范围20~120Hz的超低音。其实5.1声音系统来源于4.1环绕,不同之处在于它增加了一个中置单元。这个中置单元负责传送低于80Hz的声音信号,在欣赏影片时有利于加强人声,把对话集中在整个声场的中部,以增加整体效果。相信每一个真正体验过Dolby AC-3音效的朋友都会为5.1声道所折服。
流特征
随着网络的发展,人们对在线收听音乐提出了要求,因此也要求音频文件能够一边读一边播放,而不需要把这个文件全部读出后然后回放,这样就可以做到不用下载就可以实现收听了;也可以做到一边编码一边播放,正是这种特征,可以实现在线的直播,架设自己的数字广播电台成为了现实。
编码分类
根据编码方式的不同,音频编码技术分为三种:波形编码、参数编码和混合编码。一般来说,波形编码的话音质量高,但编码速率也很高;参数编码的编码速率很低,产生的合成语音的音质不高;混合编码使用参数编码技术和波形编码技术,编码速率和音质介于它们之间。
1、波形编码
波形编码是指不利用生成音频信号的任何参数,直接将时间域信号变换为数字代码,使重构的语音波形尽可能地与原始语音信号的波形形状保持一致。波形编码的基本原理是在时间轴上对模拟语音信号按一定的速率抽样,然后将幅度样本分层量化,并用代码表示。 波形编码方法简单、易于实现、适应能力强并且语音质量好。不过因为压缩方法简单也带来了一些问题:压缩比相对较低,需要较高的编码速率。一般来说,波形编码的复杂程度比较低,编码速率较高、通常在16 kbit/s以上,质量相当高。但编码速率低于16 kbit/s时,音质会急剧下降。 最简单的波形编码方法是PCM(Pulse Code Modulation,脉冲编码调制),它只对语音信号进行采样和量化处理。优点是编码方法简单,延迟时间短,音质高,重构的语音信号与原始语音信号几乎没有差别。不足之处是编码速率比较高(64 kbit/s),对传输通道的错误比较敏感。
2、参数编码
参数编码是从语音波形信号中提取生成语音的参数,使用这些参数通过语音生成模型重构出语音,使重构的语音信号尽可能地保持原始语音信号的语意。也就是说,参数编码是把语音信号产生的数字模型作为基础,然后求出数字模型的模型参数,再按照这些参数还原数字模型,进而合成语音。 参数编码的编码速率较低,可以达到2.4 kbit/s,产生的语音信号是通过建立的数字模型还原出来的,因此重构的语音信号波形与原始语音信号的波形可能会存在较大的区别、失真会比较大。而且因为受到语音生成模型的限制,增加数据速率也无法提高合成语音的质量。不过,虽然参数编码的音质比较低,但是保密性很好,一直被应用在军事上。典型的参数编码方法为LPC(Linear Predictive Coding,线性预测编码)。
3、混合编码
混合编码是指同时使用两种或两种以上的编码方法进行编码。这种编码方法克服了波形编码和参数编码的弱点,并结合了波形编码高质量和参数编码的低编码速率,能够取得比较好的效果。
编码格式
PCM编码
PCM 脉冲编码调制是Pulse Code Modulation的缩写。前面的文字我们提到了PCM大致的工作流程,我们不需要关心PCM最终编码采用的是什么计算方式,我们只需要知道PCM编码的音频流的优点和缺点就可以了。PCM编码的最大的优点就是音质好,最大的缺点就是体积大。我们常见的Audio CD就采用了PCM编码,一张光盘的容量只能容纳72分钟的音乐信息。 WAV格式 这是一种古老的音频文件格式,由微软开发。WAV是一种文件格式,符合RIFF (Resource Interchange File Format) 规范。所有的WAV都有一个文件头,这个文件头包含了音频流的编码参数。WAV对音频流的编码没有硬性规定,除了PCM之外,还有几乎所有支持ACM规范的编码都可以为WAV的音频流进行编码。很多朋友没有这个概念,我们拿AVI做个示范,因为AVI和WAV在文件结构上是非常相似的,不过AVI多了一个视频流而已。我们接触到的AVI有很多种,因此我们经常需要安装一些Decode才能观看一些AVI,我们接触到比较多的DivX就是一种视频编码,AVI可以采用DivX编码来压缩视频流,当然也可以使用其他的编码压缩。同样,WAV也可以使用多种音频编码来压缩其音频流,不过我们常见的都是音频流被PCM编码处理的WAV,但这不表示WAV只能使用PCM编码,MP3编码同样也可以运用在WAV中,和AVI一样,只要安装好了相应的Decode,就可以欣赏这些WAV了。 在Windows平台下,基于PCM编码的WAV是被支持得最好的音频格式,所有音频软件都能完美支持,由于本身可以达到较高的音质的要求,因此,WAV也是音乐编辑创作的首选格式,适合保存音乐素材。因此,基于PCM编码的WAV被作为了一种中介的格式,常常使用在其他编码的相互转换之中,例如MP3转换成WMA。
MP3编码
动态图像专家组-1或动态图像专家组-2 音频层III(MPEG-1 or MPEG-2 Audio Layer III),经常称为MP3,是当今相当流行的一种数字音频编码和有损压缩格式,它被设计来大幅降低音频数据量,它舍弃PCM音讯资料中,对人类听觉不重要的资料,从而达到了压缩成较小的档案。而对于大多数用户的听觉感受来说,MP3的音质与最初的不压缩音频相比没有明显的下降。它是在1991年,由位于德国埃尔朗根的研究组织Fraunhofer-Gesellschaft的一组工程师发明和标准化的。MP3的普及,曾对音乐产业造成冲击与影响。 MP3是一个数据压缩格式。它舍弃脉冲编码调制(PCM)音频数据中,对人类听觉不重要的数据(类似于JPEG是一个有损图像压缩),从而达到了压缩成小得多的文件大小。
在MP3中使用了许多技术,其中包括心理声学,以确定音频的哪一部分可以丢弃。MP3音频可以按照不同的比特率进行压缩,提供了权衡数据大小和音质之间的依据。
MP3格式使用了混合的转换机制将时域信号转换成频域信号:
- 32波段多相积分滤波器(PQF)
- 36或者12 tap 改良离散余弦滤波器(MDCT);每个子波段大小可以在0…1和2…31之间独立选择
- 混叠衰减后处理
尽管有许多创造和推广其他格式的重要努力,如 MPEG 标准中的 AAC(Advanced Audio Coding)和 Xiph.Org 开源无专利的 Ogg Vorbis。然而,由于MP3的空前的流通,在目前来说,其他格式不可能威胁其地位。MP3不仅有广泛的用户端软体支持,也有很多的硬件支持,比如便携式数位音频播放器(泛指MP3播放器)、移动电话、DVD和CD播放器。
MP3作为目前最为普及的音频压缩格式,为大家所大量接受,各种与MP3相关的软件产品层出不穷,而且更多的硬件产品也开始支持MP3,我们能够买到的VCD/DVD播放机都很多都能够支持MP3,还有更多的便携的MP3播放器等等,虽然几大音乐商极其反感这种开放的格式,但也无法阻止这种音频压缩的格式的生存与流传。MP3发展已经有10个年头了,他是MPEG(MPEG:Moving Picture Experts Group) Audio Layer-3的简称,是MPEG1的衍生编码方案,1993年由德国Fraunhofer IIS研究院和汤姆生公司合作发展成功。MP3可以做到12:1的惊人压缩比并保持基本可听的音质,在当年硬盘天价的日子里,MP3迅速被用户接受,随着网络的普及,MP3被数以亿计的用户接受。MP3编码技术的发布之初其实是非常不完善的,由于缺乏对声音和人耳听觉的研究,早期的mp3编码器几乎全是以粗暴方式来编码,音质破坏严重。随着新技术的不断导入,mp3编码技术一次一次的被改良,其中有2次重大技术上的改进。
发展 MPEG-1 Audio Layer II编码开始时是德国Deutsche Forschungs- und Versuchsanstalt für Luft- und Raumfahrt(后来称为Deutsches Zentrum für Luft- und Raumfahrt, 德国太空中心)Egon Meier-Engelen管理的数字音频广播(DAB)项目。这个项目是欧盟作为EUREKA研究项目资助的,它的名字通常称为EU-147。EU-147的研究期间是1987年到1994年。
到了1991年,就已经出现了两个提案:Musicam(称为Layer 2)和ASPEC(自适应频谱感知熵编码)。荷兰飞利浦公司、法国CCETT和德国Institut für Rundfunktechnik提出的Musicam方法由于它的简单、出错时的稳定性以及在高质量压缩时较少的计算量而被选中。基于子带编码的Musicam格式是确定MPEG音频压缩格式(采样率、帧结构、数据头、每帧采样点)的一个关键因素。这项技术和它的设计思路完全融合到了ISO MPEG Audio Layer I、II以及后来的Layer III(MP3)格式的定义中。在Mussmann教授(汉诺威大学)的主持下,标准的制定由Leon van de Kerkhof(Layer I)和Gerhard Stoll(Layer II)完成。
一个由荷兰Leon Van de Kerkhof、德国Gerhard Stoll、法国Yves-François Dehery和德国Karlheinz Brandenburg组成的工作小组吸收了Musicam和ASPEC的设计思想,并添加了他们自己的设计思想从而开发出了MP3,MP3能够在128kbit/s达到MP2 192kbit/s音质。
所有这些算法最终都在1992年成为了MPEG的第一个标准组MPEG-1的一部分,并且生成了1993年公布的国际标准ISO/IEC 11172-3。MPEG音频上的更进一步的工作最终成为了1994年制定的第二个MPEG标准组MPEG-2标准的一部分,这个标准正式的称呼是1995年首次公布的ISO/IEC 13818-3。
编码器的压缩效率通常由比特率定义,因为压缩率依赖于位数(bit depth)和输入信号的采样率。然而,经常有产品使用CD参数(44.1kHz、两个通道、每通道16位或者称为2x16位)作为压缩率参考,使用这个参考的压缩率通常较高,这也说明了压缩率对于有损压缩存在的问题。
Karlheinz Brandenburg使用CD介质的Suzanne Vega的歌曲Tom’s Diner来评价MP3压缩算法。使用这首歌是因为这首歌的柔和、简单旋律使得在回放时更容易听到压缩格式中的缺陷。一些人开玩笑地将Suzanne Vega称为“MP3之母”。来自于EBU V3/SQAM参考CD的更多一些严肃和critical音频选段(钟琴,三角铁,手风琴,…)被专业音频工程师用来评价MPEG音频格式的主观感受质量。
MP3走向大众 为了生成位兼容的MPEG Audio文件(Layer 1、Layer 2、Layer 3),ISO MPEG Audio委员会成员用C语言开发的一个称为ISO 11172-5的参考模拟软件。在一些非实时操作系统上它能够演示第一款压缩音频基于DSP的实时硬件解码。一些其他的MPEG Audio实时开发出来用于面向消费接收机和机顶盒的数字广播(无线电DAB和电视DVB)。
后来,1994年7月7日Fraunhofer-Gesellschaft发布了第一个称为l3enc的MP3编码器。
Fraunhofer开发组在1995年7月14日选定扩展名:”.mp3”(以前扩展名是”.bit”)。使用第一款实时软件MP3播放器Winplay3(1995年9月9日发布)许多人能够在自己的个人电脑上编码和回放MP3文件。由于当时的硬盘相对较小(如500MB),这项技术对于在计算机上存储娱乐音乐来说是至关重要的。
MP2、MP3与因特网 1993年10月,MP2(MPEG-1 Audio Layer 2)文件在因特网上出现,它们经常使用Xing MPEG Audio Player播放,后来又出现了Tobias Bading为Unix开发的MAPlay。MAPlay于1994年2月22日首次发布,现在已经移植到微软视窗平台上。
刚开始仅有的MP2编码器产品是Xing Encoder和CDDA2WAV,CDDA2WAV是一个将CD音轨转换成WAV格式的CD抓取器。
Internet Underground Music Archive(IUMA)通常被认为是在线音乐革命的鼻祖,IUMA是因特网上第一个高保真音乐网站,在MP3和网络流行之前它有数千首授权的MP2录音。
从1995年上半年开始直到整个九十年代后期,MP3开始在因特网上蓬勃发展。MP3的流行主要得益于如Nullsoft于1997年发布的Winamp和于1999年发布的Napster,这样的公司和软件包的成功,并且它们相互促进发展。这些程序使得普通用户很容易地播放、制作、共享和收集MP3文件。
关于MP3文件的点对点技术文件共享的争论在最近几年迅速蔓延—这主要是由于压缩使得文件共享成为可能,未经压缩的文件过于庞大难于共享。由于MP3文件通过因特网大量传播,一些主要唱片厂商通过法律起诉Napster来保护它们的版权(参见知识产权)。
如iTunes Store这样的商业在线音乐发行服务通常选择其他或者专有的支持数字版权管理(DRM)的音乐文件格式以控制和限制数字音乐的使用。支持DRM的格式的使用是为了防止受版权保护的素材免被侵犯版权,但是大多数的保护机制都能被一些方法破解。这些方法能够被计算机高手用来生成能够自由复制的解锁文件。如果希望得到一个压缩的音频文件,这个录制的音频流必须进行压缩且代价是音质的降低。 比特率 比特率对于MP3文件来说是可变的。总的原则是比特率越高则声音文件中包含的原始声音信息越多,这样回放时声音质量也越高。在MP3编码的早期,整个文件使用一个固定的比特率,称为固定码率(CBR)。
MPEG-1 Layer 3允许使用的比特率是32、40、48、56、64、80、96、112、128、160、192、224、256和320 kbit/s,允许的采样频率是32、44.1和48kHz。44.1kHz是最为经常使用的速度(与CD的采样速率相同),128kbit/s是事实上“好品质”的标准,尽管320kbit/s在P2P文件共享网络上越来越受到欢迎。MPEG-2和[非正式的]MPEG-2.5包括其他一些比特率:6、12、24、32、40、48、56、64、80、96、112、128、144、160kbit/s。
可变码率(VBR)也是可能的。MP3文件的中的音频切分成有自己不同比特率的帧,这样在文件编码的时候就可以动态地改变比特率。尽管在最初的实现中并没有这项功能。VBR技术现在音频/视频编码领域已经得到了广泛的应用,这项技术使得在声音变化大的部分使用较大的比特率而在声音变化小的部分使用较小的比特率成为可能。这个方法类似于声音控制的磁带录音机不记录静止部分节省磁带消耗。一些编码器在很大程度上依赖于这项技术。
高达640kbit/s的比特率可以使用LAME编码器和自由格式来实现,但是由于它并非标准比特率之一,有些低端或早期的MP3播放器不能够播放这些文件。
MP3的音频质量 因为MP3是一种有损压缩格式,它提供了多种不同“比特率”(bit rate)的选项—也就是用来表示每秒音频所需的编码数据位数。典型的速度介于128kbps和320kbps(kbit/s)之间。与此对照的是,CD上未经压缩的音频比特率是1411.2 kbps(16位/采样点× 44100采样点/秒× 2通道)。
使用较低比特率编码的MP3文件通常回放质量较低。使用过低的比特率,“压缩噪声(compression artifact)”(原始录音中没有的声音)将会在回放时出现。说明压缩噪声的一个好例子是:压缩欢呼的声音;由于它的随机性和急剧变化,所以编码器的错误就会更明显,并且听起来就象回声。
除了编码文件的比特率之外;MP3文件的质量,也与编码器的质量以及编码信号的难度有关。使用优质编码器编码的普通信号,一些人认为128kbit/s的MP3以及44.1kHz的CD采样的音质近似于CD音质,同时得到了大约11:1的压缩率。在这个比率下正确编码的MP3只能够获得比调频广播更好的音质,这主要是那些模拟介质的带宽限制、信噪比和其他一些限制。然而,听力测试显示经过简单的练习测试听众能够可靠地区分出128kbit/s MP3与原始CD的区别[来源请求]。在许多情况下他们认为MP3音质不佳是不可接受的,然而其他一些听众或者换个环境(如在嘈杂的车中或者聚会上)他们又认为音质是可接受的。很显然,MP3编码的瑕疵在低端声卡或者扬声器上比较不明显,而在连接到计算机的高质量立体声系统,尤其是使用高保真音响设备或者高质量的耳机时则比较明显。
Fraunhofer Gesellschaft(FhG)在他们的官方网站上,公布了下面的MPEG-1 Layer 1/2/3的压缩率和数据速率用于比较:
- Layer 1: 384 kbit/s,压缩率4:1
- Layer 2: 192 - 256 kbit/s,压缩率8:1-6:1
- Layer 3: 112 - 128 kbit/s,压缩率12:1-10:1 不同层面之间的差别是因为它们使用了不同的心理声学模型导致的;Layer 1的算法相当简单,所以透明编码就需要更高的比特率。然而,由于不同的编码器使用不同的模型,很难进行这样的完全比较。
许多人认为所引用的速率,出于对Layer 2和Layer 3记录的偏爱,而出现了严重扭曲。他们争辩说实际的速率如下所列:
- Layer 1: 384 kbit/s优秀
- Layer 2: 256 - 384 kbit/s优秀,224 - 256 kbit/s很好,192 - 224 kbit/s好
- Layer 3: 224 - 320 kbit/s优秀,192 - 224 kbit/s很好,128 - 192 kbit/s好
当比较压缩机制时,很重要的是要使用同等音质的编码器。将新编码器与基于过时技术甚至是带有缺陷的旧编码器比较可能会产生对于旧格式不利的结果。由于有损编码会丢失信息这样一个现实,MP3算法通过创建人类听觉总体特征的模型尽量保证丢弃的部分不被人耳识别出来(例如,由于noise masking),不同的编码器能够在不同程度上实现这一点。
一些可能的编码器:
- Mike Cheng在1998年早些时候首次开发的LAME。与其他相比,它是一个完全遵循LGPL的MP3编码器,它有良好的速度和音质,甚至对MP3技术的后继版本形成了挑战[来源请求]。
- Fraunhofer Gesellschaft:有些编码器不错,有些有缺陷。 有许多的早期编码器现在已经不再广泛使用:
- ISO dist10
- BladeEnc
- ACM Producer Pro.
好的编码器能够在128到160kbit/s下达到可接受的音质,在160到192kbit/s下达到接近透明的音质。所以不在特定编码器或者最好的编码器话题内说128kbit/s或者192kbit/s下的音质是容易引起误解的。一个好的编码器在128kbit/s下生成的MP3有可能比一个不好的编码器在192kbit/s下生成的MP3音质更好。另外,即使是同样的编码器同样的文件大小,一个不变比特率的MP3可能比一个变比特率的MP3音质要差很多。
需要注意的一个重要问题是音频信号的质量是一个主观判断。安慰效果(Placebo effect)是很严重的,许多用户声明要有一定水准的透明度。许多用户在A/B测试中都没有通过,他们无法在更低的比特率下区分文件。一个特定的比特率对于有些用户来说是足够的,对于另外一些用户来说是不够的。每个人的声音感知可能有所不同,所以一个能够满足所有人的特定心理声学模型并不明显存在。仅仅改变试听环境,如音频播放系统或者环境可能就会显现出有损压缩所产生的音质降低。上面给出的数字只是大多数人的一个大致有效参考,但是在有损压缩领域真正有效的压缩过程质量测试手段就是试听音频结果。
如果你的目标是实现没有质量损失的音频文件或者用在演播室中的音频文件,就应该使用无损压缩(Lossless)算法,目前能够将16位PCM音频数据压缩到38%并且声音没有任何损失,这样的无损压缩编码有LA、Sony ATRAC Advanced Lossless、Dolby TrueHD、DTS Master Lossless Audio、MLP、Sony Reality Audio、WavPack、Apple Lossless、TTA、FLAC、Windows Media Audio 9 Lossless(WMA)和APE(Monkey’s Audio)等等。
对于需要进行编辑、混合处理的音频文件要尽量使用无损格式,否则有损压缩产生的误差可能在处理后无法预测,多次编码产生的损失将会混杂在一起,在处理之后进行编码这些损失将会变得更加明显。无损压缩在降低压缩率的代价下能够达到最好的结果。
一些简单的编辑操作,如切掉音频的部分片段,可以直接在MP3数据上操作而不需要重新编码。对于这些操作来说,只要使用合适的软件(”mp3DirectCut”和”MP3Gain”),上面提到的问题可以不必考虑。
MP3的设计限制 MP3格式存有设计限制,即使使用更好的编码器仍旧不能克服这些限制。一些新的压缩格式如AAC、Ogg Vorbis等不再有这些限制。
按照技术术语,MP3有如下一些限制:
- 编码的比特率位速最高质量可达320Kbps,基本不损失原本音效质量[4]。
- 时间分辨率相对于变化迅速的信号来说太低。
- 采样频率最高为48kHz,对于超过48kHz采样频率的音频无法编码在MP3内,而CD经常使用的采样速率为44.1kHz。
- 联合立体声(Joint stereo)是基于帧与帧完成的。
- 没有定义编码器/解码器的整体时延,这就意味着gapless playback缺少一个正式的规定。 然而,即使有这些限制,一个经良好的调整MP3编码器仍能够提供与其他格式相提并论或更高的编码质量。
MPEG-1标准中没有MP3编码器的一个精确规范,然而与此相反,解码算法和文件格式却进行了细致的定义。人们设想编码的实现是设计自己的适合去除原始音频中部分信息的算法(或者是它在频域中的修正离散余弦(MDCT)表示)。在编码过程中,576个时域样本被转换成576个频域样本,如果是瞬变信号就使用192而不是576个采样点,这是限制量化噪声随着随瞬变信号短暂扩散。
这是听觉心理学的研究领域:人类主观声音感知。
这样带来的结果就是出现了许多不同的MP3编码器,每种生成的声音质量都不相同。有许多它们的比较结果,这样一个潜在用户很容易选择合适的编码器。需要记住的是高比特率编码表现优秀的编码器(如LAME这个在高比特率广泛使用的编码器)未必在低比特率的表现也同样好。
MP3音频编码 MPEG-1标准中没有MP3编码器的一个精确规范,然而与此相反,解码算法和文件格式却进行了细致的定义。人们设想编码的实现是设计自己的适合去除原始音频中部分信息的算法(或者是它在频域中的修正离散余弦(MDCT)表示)。在编码过程中,576个时域样本被转换成576个频域样本,如果是瞬变信号就使用192而不是576个采样点,这是限制量化噪声随着随瞬变信号短暂扩散。
这是听觉心理学的研究领域:人类主观声音感知。
这样带来的结果就是出现了许多不同的MP3编码器,每种生成的声音质量都不相同。有许多它们的比较结果,这样一个潜在用户很容易选择合适的编码器。需要记住的是高比特率编码表现优秀的编码器(如LAME这个在高比特率广泛使用的编码器)未必在低比特率的表现也同样好。
MP3音频解码 另一方面,解码在标准中进行了细致的定义。
多数解码器是bitstream compliant,也就是说MP3文件解码出来的非压缩输出信号将与标准文档中数学定义的输出信号一模一样(在规定的近似误差范围内)。
MP3文件有一个标准的格式,这个格式就是包括384、576、或者1152个采样点(随MPEG的版本和层不同而不同)的帧,并且所有的帧都有关联的头信息(32位)和辅助信息(9、17或者32字节,随着MPEG版本和立体声或者单通道的不同而不同)。头和辅助信息能够帮助解码器正确地解码相关的霍夫曼编码数据。
所以,大多数的解码器比较几乎都是完全基于它们的计算效率(例如,它们在解码过程中所需要的内存或者CPU时间)。
关于VBR VBR:MP3格式的文件有一个有意思的特征,就是可以边读边放,这也符合流媒体的最基本特征。也就是说播放器可以不用预读文件的全部内容就可以播放,读到哪里播放到哪里,即使是文件有部分损坏。虽然mp3可以有文件头,但对于mp3格式的文件却不是很重要,正因为这种特性,决定了MP3文件的每一段每一帧都可以单独的平均数据速率,而无需特别的解码方案。于是出现了一种叫VBR(Variable bitrate,动态数据速率)的技术,可以让MP3文件的每一段甚至每一帧都可以有单独的bitrate,这样做的好处就是在保证音质的前提下最大程度的限制了文件的大小。这种技术的优越性是显而易见的,但要运用确实是一件难事,因为这要求编码器知道如何为每一段分配bitrate,这对没有波形分析的编码器而言,这种技术如同虚设。正是如此,VBR技术并没有一出现就显得光彩夺目。 专家们通过长期的声学研究,发现人耳存在 遮蔽效应。声音信号实际是一种能量波,在空气或其他媒介中传播,人耳对声音能量的多少即响度或声压最直接的反应就是听到这个声音的大小,我们称它为响度,表示响度这种能量的单位为分贝(dB)。即使是同样响度的声音,人们也会因为它们频率不同而感觉到声音大小不同。人耳最容易听到的就是4000Hz的频率,不管频率是否增高或降低,即使是响度在相同的情况下,大家都会觉得声音在变小。但响度降到一定程度时,人耳就听不到了,每一个频率都有着不同的值。 可以看到这条曲线基本成一个V字型,当频率超过15000Hz时,人耳的会感觉到声音很小,很多听觉不是很好的人,根本就听不到20000Hz的频率,不管响度有多大。当人耳同时听到两个不同频率、不同响度的声音时,响度较小的那个也会被忽略,例如:在白天我们很难听到电脑中散热风扇的声音,晚上却成了噪声源,根据这种原理,编码器可以过滤掉很多听不到的声音,以简化信息复杂度,增加压缩比,而不明显的降低音质。这种遮蔽被称为同时遮蔽效应。但声音A被声音B遮蔽,如果A处于B为中心的遮蔽范围内,遮蔽会更明显,这个范围叫临界带宽。每一种频率的临界带宽都不一样,频率越高的临界带宽越宽。
频率(Hz) 临界带宽(Hz) 频率(Hz) 临界带宽(Hz) 根据这种效应,专家们设计出人耳听觉心理模型,这个模型被导入到mp3编码中后,导致了一场翻天覆地的音质革命,mp3编码技术一直背负着音质差的恶名,但这个恶名现在已经逐渐被洗脱。到了此时,一直被埋没的VBR技术光彩四射,配合心理模型的运用便现实出强大的诱惑力与杀伤力。 长期来,很多人对MP3印象不好,更多人认为WMA的最佳音质要好过MP3,这种说法是不正确的,在中高码率下,编码得当的MP3要比WMA优秀很多,可以非常接近CD音质,在不太好的硬件设备支持下,没有多少人可以区分两者的差异,这不是神话故事,尽管你以前盲听就可以很轻松区分MP3和CD,但现在你难保证你可以分辨正确。因为MP3是优秀的编码,以前被埋没了。
OGG编码
网络上出现了一种叫Ogg Vorbis的音频编码,号称MP3杀手!Ogg Vorbis究竟什么来头呢?OGG是一个庞大的多媒体开发计划的项目名称,将涉及视频音频等方面的编码开发。整个OGG项目计划的目的就是向任何人提供完全免费多媒体编码方案!OGG的信念就是:OPEN!FREE!Vorbis这个词汇是特里·普拉特柴特的幻想小说《Small Gods》中的一个”花花公子”人物名。这个词汇成为了OGG项目中音频编码的正式命名。目前Vorbis已经开发成功,并且开发出了编码器。 Ogg Vorbis是高质量的音频编码方案,官方数据显示:Ogg Vorbis可以在相对较低的数据速率下实现比MP3更好的音质!Ogg Vorbis这种编码也远比90年代开发成功的MP3先进,它可以支持多声道,这意味着什么?这意味着Ogg Vorbis在SACD、DTSCD、DVD AUDIO抓轨软件(目前这种软件还没有)的支持下,可以对所有的声道进行编码,而不是MP3只能编码2个声道。多声道音乐的兴起,给音乐欣赏带来了革命性的变化,尤其在欣赏交响时,会带来更多临场感。这场革命性的变化是MP3无法适应的。 和MP3一样,Ogg Vorbis是一种灵活开放的音频编码,能够在编码方案已经固定下来后还能对音质进行明显的调节和新算法的改良。因此,它的声音质量将会越来越好,和MP3相似,Ogg Vorbis更像一个音频编码框架,可以不断导入新技术逐步完善。和MP3一样,OGG也支持VBR。
MPC编码
MPC是又是另外一个令人刮目相看的实力派选手,它的普及过程非常低调,也没有什么复杂的背景故事,她的出现目的就只有一个,更小的体积更好的音质!MPC以前被称作MP+,很显然,可以看出她针对的竞争对手是谁。但是,只要用过这种编码的人都会有个深刻的印象,就是她出众的音质。
mp3PRO编码
2001年6月14日,美国汤姆森多媒体公司(Thomson Multimedia SA)与佛朗赫弗协会(Fraunhofer Institute)于6月14日发布了一种新的音乐格式版本,名称为mp3PRO,这是一种基于mp3编码技术的改良方案,从官方公布的特征看来确实相当吸引人。从各方面的资料显示,mp3PRO并不是一种全新的格式,完全是基于传统mp3编码技术的一种改良,本身最大的技术亮点就在于SBR(Spectral Band Replication 频段复制),这是一种新的音频编码增强算法。它提供了改善低位率情况下音频和语音编码的性能的可能。这种方法可在指定的位率下增加音频的带宽或改善编码效率。SBR最大的优势就是在低数据速率下实现非常高效的编码,与传统的编码技术不同的是,SBR更像是一种后处理技术,因此解码器的算法的优劣直接影响到音质的好坏。高频实际上是由解码器(播放器)产生的,SBR编码的数据更像是一种产生高频的命令集,或者称为指导性的信号源,这有点駇idi的工作方式。我们可以看到,mp3PRO其实是一种mp3信号流和SBR信号流的混合数据流编码。有关资料显示,SBR技术可以改善低数据流量下的高频音质,改善程度约为30%,我们不管这个30%是如何得来的,但可以事先预知这种改善可以让64kbps的mp3达到128kbps的mp3的音质水平(注:在相同的编码条件下,数据速率的提升和音质的提升不是成正比的,至少人耳听觉上是这样的),这和官方声称的64kbps的mp3PRO可以媲美128kbps的mp3的宣传基本是吻合的。
WMA格式
WMA就是Windows Media Audio编码后的文件格式,由微软开发,WMA针对的不是单机市场,是网络!竞争对手就是网络媒体市场中著名的Real Networks。微软声称,在只有64kbps的码率情况下,WMA可以达到接近CD的音质。和以往的编码不同,WMA支持防复制功能,她支持通过Windows Media Rights Manager 加入保护,可以限制播放时间和播放次数甚至于播放的机器等等。WMA支持流技术,即一边读一边播放,因此WMA可以很轻松的实现在线广播,由于是微软的杰作,因此,微软在Windows中加入了对WMA的支持,WMA有着优秀的技术特征,在微软的大力推广下,这种格式被越来越多的人所接受。
RA格式
RA就是RealAudio格式,这是各位网虫接触得非常多的一种格式,大部分音乐网站的在线试听都是采用了RealAudio,这种格式完全针对的就是网络上的媒体市场,支持非常丰富的功能。最大的闪烁点就是这种格式可以根据听众的带宽来控制自己的码率,在保证流畅的前提下尽可能提高音质。RA可以支持多种音频编码,包括ATRAC3。和WMA一样,RA不但都支持边读边放,也同样支持使用特殊协议来隐匿文件的真实网络地址,从而实现只在线播放而不提供下载的欣赏方式。这对唱片公司和唱片销售公司很重要,在各方的大力推广下,RA和WMA是目前互联网上,用于在线试听最多的音频媒体格式。
APE格式
APE是Monkey’s Audio提供的一种无损压缩格式。Monkey’s Audio提供了Winamp的插件支持,因此这就意味着压缩后的文件不再是单纯的压缩格式,而是和MP3一样可以播放的音频文件格式。这种格式的压缩比远低于其他格式,但能够做到真正无损,因此获得了不少发烧用户的青睐。在现有不少无损压缩方案种,APE是一种有着突出性能的格式,令人满意的压缩比以及飞快的压缩速度,成为了不少朋友私下交流发烧音乐的唯一选择。
格式特点
各种各样的音频编码都有其技术特征及不同场合的适用性,我们大致讲解一下如何去灵活应用这些音频编码。
PCM编码的WAV
前面就提到过,PCM编码的WAV文件是音质最好的格式,Windows平台下,所有音频软件都能够提供对她的支持。Windows提供的WinAPI中有不少函数可以直接播放wav,因此,在开发多媒体软件时,往往大量采用wav,用作事件声效和背景音乐。PCM编码的wav可以达到相同采样率和采样大小条件下的最好音质,因此,也被大量用于音频编辑、非线性编辑等领域。
- 特点:音质非常好,被大量软件所支持。
- 适用于:多媒体开发、保存音乐和音效素材。
MP3
MP3具有不错的压缩比,使用LAME编码的中高码率的mp3,听感上已经非常接近源WAV文件。使用合适的参数,LAME编码的MP3很适合于音乐欣赏。由于MP3推出年代已久,加之还算不错的音质及压缩比,不少游戏也使用mp3做事件音效和背景音乐。几乎所有著名的音频编辑软件也提供了对MP3的支持,可以将mp3象wav一样使用,但由于mp3编码是有损的,因此多次编辑后,音质会急剧下降,mp3并不适合保存素材,但作为作品的demo确实相当优秀的。mp3长远的历史和不错的音质,使之成为应用最广的有损编码之一,网络上可以找到大量的mp3资源,mp3player日渐成为一种时尚。不少VCDPlayer、DVDPlayer甚至手机都可以播放mp3,mp3是被支持的最好的编码之一。MP3也并非完美,在较低码率下表现不好。MP3也具有流媒体的基本特征,可以做到在线播放。
- 特点:音质好,压缩比比较高,被大量软件和硬件支持,应用广泛。
- 适用于:适合用于比较高要求的音乐欣赏。
OGG
Ogg是一种非常有潜力的编码,在各种码率下都有比较惊人的表现,尤其中低码率下。Ogg除了音质好之外,她还是一个完全免费的编码,这对ogg被更多支持打好了基础。Ogg有着非常出色的算法,可以用更小的码率达到更好的音质,128kbps的Ogg比192kbps甚至更高码率的mp3还要出色。Ogg的高音具有一定的金属味道,因此在编码一些高频要求很高的乐器独奏时,Ogg的这个缺陷会暴露出来。OGG具有流媒体的基本特征,但现在还没有媒体服务软件支持,因此基于ogg的数字广播还无法实现。Ogg目前的被支持的情况还不够好,无论是软件的还是硬件的,都无法和mp3相提并论。
- 特点:可以用比mp3更小的码率实现比mp3更好的音质,高中低码率下均具有良好的表现。
- 适用于:用更小的存储空间获得更好的音质(相对MP3)。
MPC
和OGG一样,MPC的竞争对手也是mp3,在中高码率下,MPC可以做到比竞争对手更好音质,在中等码率下,MPC的表现不逊色于Ogg,在高码率下,MPC的表现更是独孤求败,MPC的音质优势主要表现在高频部分,MPC的高频要比MP3细腻不少,也没有Ogg那种金属味道,是目前最适合用于音乐欣赏的有损编码。由于都是新生的编码,和Ogg际遇相似,也缺乏广泛的软件和硬件支持。MPC有不错的编码效率,编码时间要比OGG和LAME短不少。
- 特点:中高码率下,具有有损编码中最佳的音质表现,高码率下,高频表现极佳。
- 适用于:在节省大量空间的前提下获得最佳音质的音乐欣赏。
WMA
微软开发的WMA同样也是不少朋友所喜爱的,在低码率下,有着好过mp3很多的音质表现,WMA的出现,立刻淘汰了曾经风靡一时的VQF编码。有微软背景的WMA获得了很好的软件及硬件支持,Windows Media Player就能够播放WMA,也能够收听基于WMA编码技术的数字电台。因为播放器几乎存在于每一台PC上,越来越多的音乐网站都乐意使用WMA作为在线试听的首选了。除了支持环境好之外,WMA在64-128kbps码率下也具有相当出色的表现,虽然不少要求较高的朋友并不够满意,但更多要求不高的朋友接受了这种编码,WMA很快的普及开了。 - 特点:低码率下的音质表现难有对手。
- 适用于:数字电台架设、在线试听、低要求下的音乐欣赏。
mp3PRO
作为mp3的改良版本的mp3PRO表现出了相当不错的素质,高音丰满,虽然mp3PRO是通过SBR技术在播放过程中插入的,但实际听感相当不错,虽然显得有点单薄,但在64kbps的世界里已经没有对手了,甚至超过了128kbps的mp3,但很遗憾的是,mp3PRO的低频表现也象mp3一样的破,所幸的是,SBR的高频插值可以或多或少的掩盖掉这个缺陷,因此mp3PRO的低频弱势反而不如WMA那么明显。大家可以在使用RCA mp3PRO Audio Player的PRO开关来切换PRO模式和普通模式时深深的感觉到。整体而言,64kbps的mp3PRO达到了128kbps的mp3的音质水平,在高频部分还略有胜出。
- 特点:低码率下的音质之王。
- 适用于:低要求下的音乐欣赏。
APE
一种新兴的无损音频编码,可以提供50-70%的压缩比,虽然比起有损编码来太不值得一提了,但对于追求完美音质的朋友简直是天大的福音。APE可以做到真正的无损,而不仅是听起来无损,压缩比也要比类似的无损格式要好。
- 特点:音质非常好。
- 适用于:最高品质的音乐欣赏及收藏。
相关算法
音量计算
音量值计算:db=20*lg(x/2^15),其中x表示样点幅度值,db表示分贝值。
声音是一种波,PCM数据是波形的描述,音量值表示波的能量,和波的振幅相关,和各点的相对差值有关。16bits的采样值表示范围是-3276832767。把每个点依次连接起来就是声音的波形了。求音量先将数据转换成-11之间(因为位率是是精度表示,要转换成相对最大值的比例),进行傅立叶变换,提高速度使用快速傅立叶变换(FFT),求出当时的频谱图,就是各个频率的音量大小。求平均就是总音量。
FFT变换有实部数据和虚部数据,其能量值是(实部实部+虚部虚部)的开方,而声音的大小是分贝,20lg(能量值),所以频谱图各音量是10lg(实部实部+虚部虚部)
音频编码技术比较
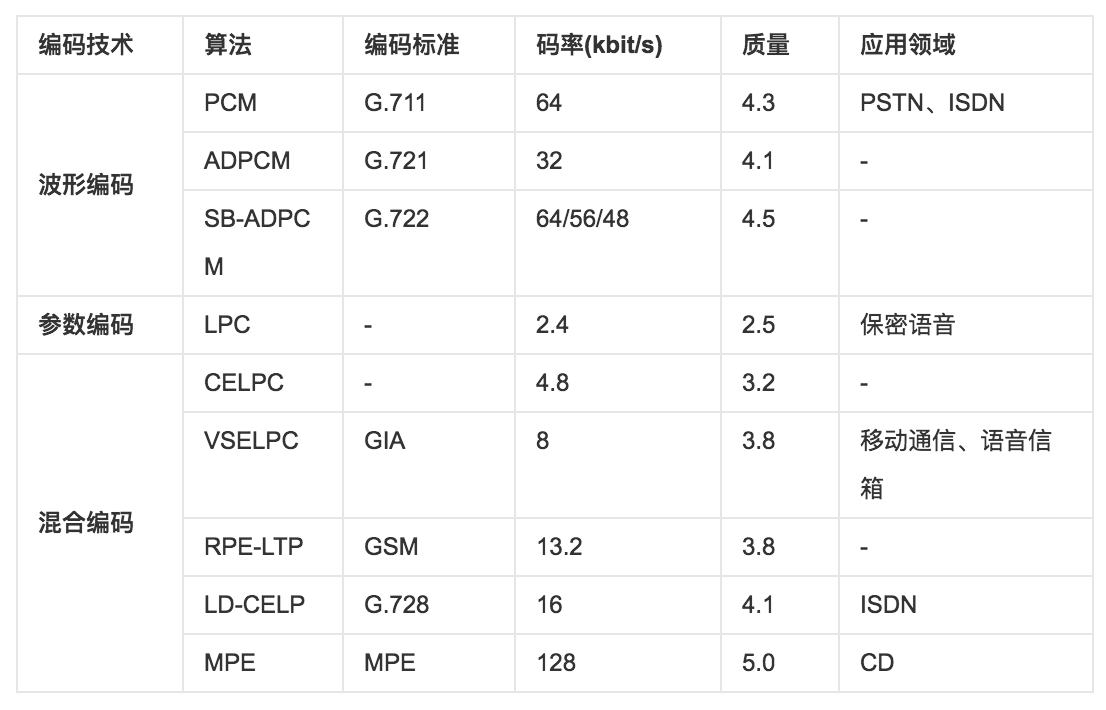 说明:质量评价共五个等级(1、2、3、4、5),其中5.0为最高分。
上表中各种算法、应用领域中缩略语的中文和英文全称参见下面说明。
说明:质量评价共五个等级(1、2、3、4、5),其中5.0为最高分。
上表中各种算法、应用领域中缩略语的中文和英文全称参见下面说明。
- PCM:Pulse Code Modulation,脉冲编码调制。
- ADPCM:Adaptive Differential Pulse Code Modulation,自适应差分脉冲编码调制。
- SB-ADPCM:Subband Adaptive Differential Pulse Code Modulation,子带-自适应差分脉冲编码调制。
- LPC:Linear Predictive Coding,线性预测编码。
- CELPC:Code Excited Linear Predictive Coding,码激励线性预测编码。
- VSELPC:Vector Sum Excited Linear Predictive Coding,矢量和激励线性预测编码。
- RPE-LTP:Regular Pulse Excited-Long Term Predictive,规则脉冲激励长时预测。
- LD-CELP:Low Delay-Code Excited Linear Predictive,低时延码激励线性预测。
- MPE:Multi-Pulse Excited,多脉冲激励。
- PSTN:Public Switched Telephone Network,公共交换电话网。
- ISDN:Integrated Services Digital Network,综合业务数字网。
Android Audio相关api
- AcousticEchoCanceler:回声消除器
- AutomaticGainControl:自动增强控制器
- NoiseSuppressor:噪音抑制器
- BassBoost:重低音调节器
- Equalizer:均衡器
- PresetReverb:预设音场控制器
- Visualizer:示波器

